MIT6.824 2021 Lab4 Sharded KV Service
阅读本文前请先仔细阅读Lab 4相关实验要求并熟悉基础代码。
- shard,即分片,一个shard是存储的kv键值对的一个子集,比如将所有开头字母为"a"的key value键值对映射作为一个shard
- 好处是可以在处理replica时,如果多次操作不同的shard可以并行处理,增加系统的吞吐量
- 在lab2和lab3中构建了一个异步Fault-tolerant KV数据库,实现了多节点之间的数据一致性,但是所有请求需要通过leader来处理,随着数据处理量越来越大,单一leader已经很难处理这种负载,因此在lab4中需要采用这种shard的方法,将数据按照某种方式分开存储到不同的集群上(group),降低单一集群的压力
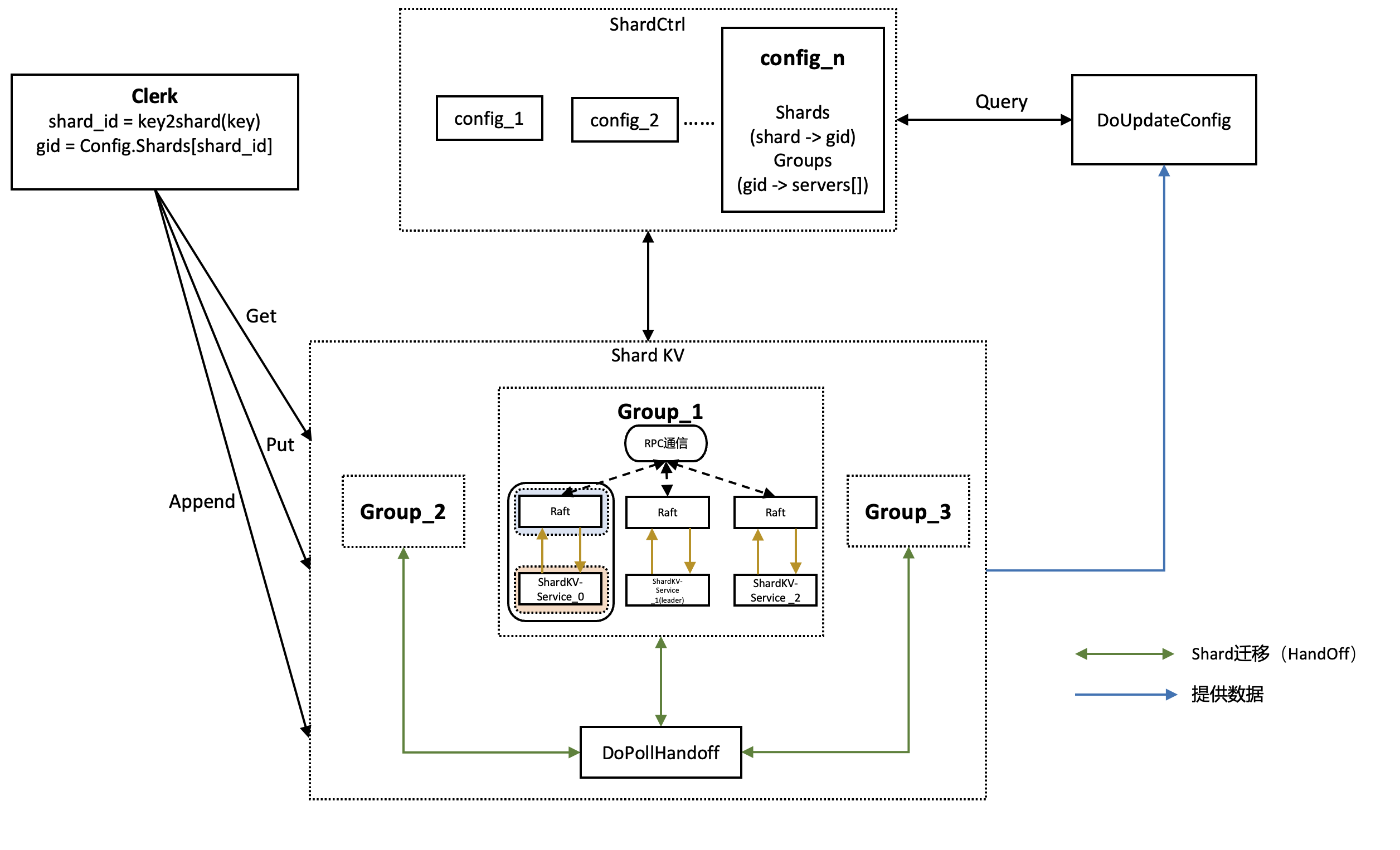
- lab4采用shard方法进行数据的划分,将不同数据划分到不同的shard上(shard之间不相交且并集为全集),再将各个shard分配到集群(groups)中,同一个阶段这样的shard与groups的对应关系称为一个配置(config)
- 随着时间的推移和数据的增加,shard需要在各个group之间进行迁移,lab4的主要挑战是在config更新和shard迁移的同时,保证提供对外的强一致性服务
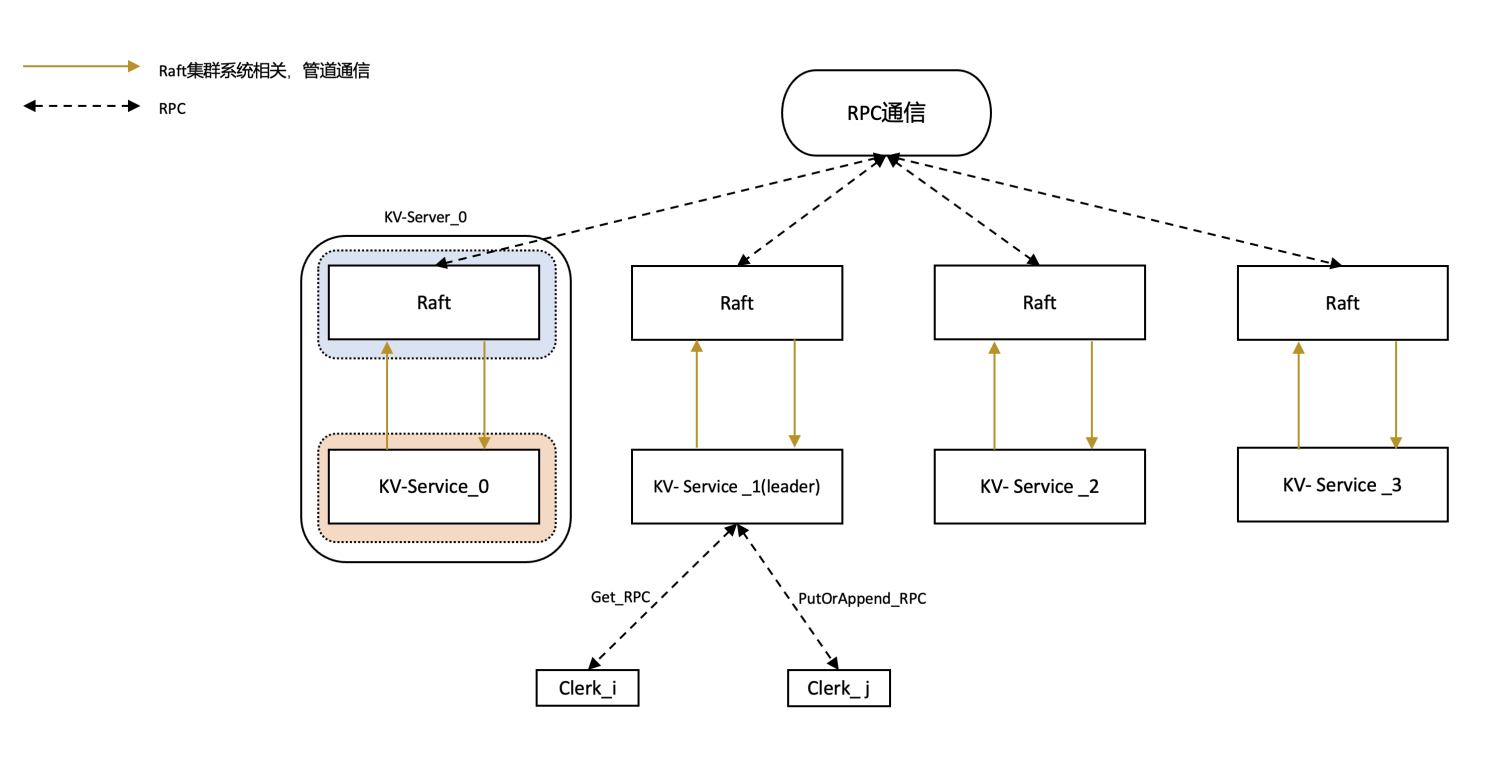
- 每个group中都有一个leader
- 一个集群只有leader才可以提供服务,lab3完成的是单个集群,而lab4完成的是多个集群协同工作
- 参考实现与代码来自于大佬,非常感谢
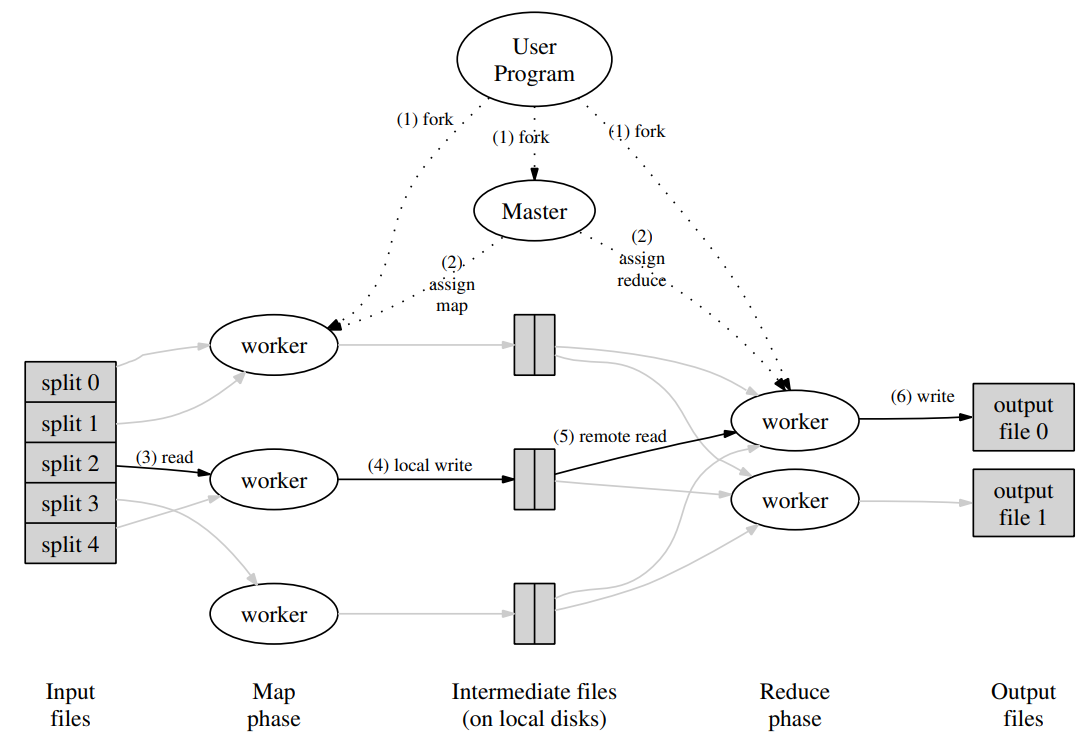
- 简易的整体结构图

Part 4A
实验说明
- Part A我们只需要完成ShardCtrl部分,这一部分是用来提供高可用的集群配置管理服务
- ShardCtrl中保存着一组config,操作最新的config(Tail),每个config记录了每一个shard(分片)分配到了哪一个group(集群)和每一个group里都有哪些server
- 需要实现下面的操作
- Move:将分片shard分配给gid的group
- Join:新加入一组group,并平衡整体的shard与group的分配
- Leave:移除groups,同时保持shard与group的平衡
- Query:查询最新的config信息,即shard与group的映射
设计概述
Move
1 | // 将Shard shard迁移到Group gid中 |
流程
- Clerk调用Move,配置好参数后通过RPC传递给ShardCtrl Server执行
- ShardCtrl Server收到Move命令后继续配置参数,并传递给Raft做group内的日志同步
- ShardCtrl Server在创建时会运行一个DoApply后台协程,当Raft服务完成日志同步并将命令commit时,DoApply协程会将该命令Apply
- Apply操作首先新建一个config,并复制最新的配置(Tail Config)给新建的config,再对该config进行操作,最后把该config添加到configs组的尾部作为最新的config
- conf.Shards[cmd.Shard] = cmd.GID
Join
1 | // 将一些group添加到系统config中 |
流程
- Apply之前的流程和Move相同
- Apply操作
- 新建一个config,并复制最新的配置(Tail Config)给新建的config
- 将参数servers复制给config的Groups,即gid -> servers[]的映射
- 由于加入了一些新的group,整体系统中shard可能会分配不均匀,影响某些group的性能,因此需要rebalance(重新分配shard),该操作后续介绍
- 在rebalance完成后将操作的config加入到configs组的尾部作为最新的config
Leave
1 | // 将gids中的group从config中删除 |
流程
- Apply之前的流程和Move相同
- Apply操作
- 新建一个config,并复制最新的配置(Tail Config)给新建的config
- 遍历config中的shard,如果发现有分配给gids中的group,则取消分配(conf.Shards[need_redistribute] = 0)
- 删除conf.Groups中的 存在于gids中的group
- 进行rebalance
- 在rebalance完成后将操作的config加入到configs组的尾部作为最新的config
Rebalance
1 | func (sc *ShardCtrler) rebalance(conf *Config); |
流程
- 对传入的config进行重新分配资源(重新分配Shards)
- 将所有现存的组号提取为一个数组并从小到大进行排序,保存在gs []int中
- 将当前Shards中保存的shard -> group的关系进行反转,即遍历conf.Shards,反转关系为group -> shards,并将数据保存在ct中
- ct := map[int][]int{0: {}} // gid -> shard[]
- for循环,直到ct中group所含shards的最大值和最小值的差值<=1退出循环
- 获取包含最多shard和最少shard的两个group,将差值一半的shard分别给两个group
- 更新conf.Shards信息
Query
1 | func (ck *Clerk) Query(num int) Config; |
流程
- 整体流程和前述Move,Join,Leave略有不同
- Clerk调用Move,配置好参数后通过RPC传递给ShardCtrl Server执行
- ShardCtrl Server收到Query命令后无需传递给Raft进行日志同步,返回最新的config作为参数通过RPC传递回Clerk即可
Code Details
- 注册自定义RPC struct
- 需要在初始化时使用labgod进行注册,否则可能会出现结构体nil错误
- 注意初始化map和channel
- 如果当前需要Apply的Command的Index小于ShardCtrl的lastApplied,说明这条Command已经过期,直接返回
- 如何避免Command重复执行的问题?
- 同Lab 3中的方法,使用一个dedup映射,保存每一个Client上一次执行的最新命令,同时在Clerk向Server传递参数时,配置变量RequestId,用来唯一确定这条命令
- dedup map[int64]interface{}
- 在Raft层提交Command给应用层Apply时,判断这条Command是否被执行过,如果这条Command相同,并且RequestId也相同,可以确定是条重复命令,无需执行直接返回即可
- 同Lab 3中的方法,使用一个dedup映射,保存每一个Client上一次执行的最新命令,同时在Clerk向Server传递参数时,配置变量RequestId,用来唯一确定这条命令
- 执行完Move,Join,Leave后需要保存command到dedup中,并更新ShardCtrl的lastApplied
Part 4B
实验说明
- Part 4A的ShardCtrl完成了配置更新,shard rebalance等任务,而Part 4B需要完成所有shard的读写任务,并保证在同一集群内的数据同步
- 相比于Lab3提供的基础读写服务,本次Lab还需要进行配置更新,shard迁移,shard数据清理,空日志监测等任务
设计概述
整体流程
- 配置需要传入group的参数(操作类型,ClientId,num,key-value等)
- 使用key2shard(key string),找到当前key被分配到了哪一个shard
- 根据shard从conf.Shards中获取group id
- 在group中循环寻找该group的leader,找到leader后调用对应命令(Put/Get/Append)的RPC,直到返回请求成功或遍历整个group
- 最后Query最新的配置
Clerk
Clerk部分较为简单,只需要实现Put/Get/Append三个操作,且流程相似,基础代码都已经给出,只需要添加一些RPC参数设置即可。
在Clerk中添加一个num成员变量(SequenceNum),作为参数传递给Shard KV Server,保存在Shard KV Server的dedup映射中,原理同Lab4A,用来唯一标记当前执行Command,每当调用一次 Put/Get/Append 就自增。在Shard KV Server中通过ClientId -> SequenceNum的映射dedup进行Command去重。
Server
由于需要对Shard进行迁移操作,为Shard设置了三个状态
1 | const ( |
只有在Shard处于Serving状态下,才能对该shard进行Get/Put/Append操作。
Pulling状态说明该Shard还未到位,正在等待从其他Group中拉取。
Pushing状态说明该shard需要handoff给其他Group。
同时为了保证系统的异步性,设置了三个后台协程:
- DoApply
- 功能和Lab 2 Lab 3中的DoApply协程相同,监听从Raft层传来的需要apply的Command
- 如果传来Command的类型是Config则更新配置
- 遍历旧配置中的shard与gid的映射
- 如果shard对应的gid等于自己所在的group,且新配置中的shard对应的gid不等于自己所在的group,说明需要将shard迁移到别的group,因此将该ShardState置为Pushing状态,并将shard加入到handoff[]数组中,准备作为参数传递给需要接受的group
- 如果shard对应的gid不等于自己所在的group,且新配置中的shard对应的gid等于自己所在的group,说明需要将该shard从其他group迁移过来,因此将该ShardState置为Pulling状态
- 执行handoff(只有leader才可以执行)
- 向handoff管道中发送需要移动给其他group的shard(handoff[]数组)(其他group只能由leader接受)
- 遍历旧配置中的shard与gid的映射
- 如果传来Command的类型为其他
- Get类型:确保key所对应的shard处于serving状态,返回key对应的value
- PutAppend类型:确保key所对应的shard处于serving状态,判断该Command是否重复后进行Put/Append操作,并更新dedup映射
- Handoff类型:这类型的命令是用来接收其他group传递给自身server的shard(key-value键值对)。首先判断该Command是否重复,判断该版本号是否一致,遍历Shards确定是否所有的shard都处于serving状态,如果都处于serving状态,无需更新直接返回,如果不是,则将传入参数的kv数据库添加到group原有的kv数据库中,接着将全部shard更新为serving,最后更新dedup映射和SequenceNum,避免重复执行相关命令
- HandoffDone类型:这类型的命令是判断自己之前发出的Handoff命令是否完成。判断该Command的版本号是否和当前一致,不一致直接返回,一致的情况下,说明之前执行的Handoff命令已经成功完成,因此可以删除掉已经移交的Keys,并将对应的Shards的状态设置为serving
- 如果传来Command的类型是Config则更新配置
- 功能和Lab 2 Lab 3中的DoApply协程相同,监听从Raft层传来的需要apply的Command
- DoUpdateConfig
- 每隔一段UpdateConfigInterval时间,使用Query查询(ShardCtrl)拉取新的Config,如果拉取到新的Config,则将其传入Raft层中提交日志并进行同步,以此更新每个机器上的Config
- 只有在Group中每个Shard都处于Serving状态时才能进行config的拉取
- DoPollHandoff
- 这个协程的作用是用来协调各个group之间的handoff RPC,共两类
- sendHandoff RPC,由发送方调用,发送方为需要进行handoff的group中的server,发送给目的group中的leader
- sendHandoffDone RPC,由目的group中的leader调用,再完成Raft同步并apply后,调用此RPC向原group中的leader发送已经完成Handoff的信息
- 持续监听自身handoff管道,即在DoApply中传送的数据,接收到数据说明需要将自身的一些shard传递给其他的group
- 遍历需要传送数据的group,配置好参数后调用sendHandoff RPC对Group中的leader进行handoff(shard迁移)
- leader收到handoff RPC后,解析参数,传递给Raft层进行同步,同步完成后交给DoApply协程进行Command分析并apply
- 如果apply成功,则配置HandoffDone参数,调用sendHandoffDone RPC,传递回给发起Handoff的Group,原Group收到HandoffDone参数后传递给Raft层同步,同步完成后交给DoApply协程进行Command分析并Apply
- 如果遍历完后并没有找到可以发送RPC的server,等待UpdateConfigPollInterval后继续轮询group进行遍历
- 这个协程的作用是用来协调各个group之间的handoff RPC,共两类
Snapshot
Snapshot的过程发生在DoApply中,当执行完一条命令发现kv.rf.GetStateSize() >= kv.maxraftstate时,调用rf.Snapshot()进行快照。
同样在DoApply中,发现传入的命令是Snapshot,则调用rf.CondInstallSnapshot()进行Raft服务层的Snapshot安装,如果安装成功,则进行KV Server的Snapshot安装。
Challenge
这部分实现更多讲解和细节可以参考原大佬的文章,做了部分搬运。
在上面的设计中已经包含Challenge的部分实现,此处做进一步说明。
Garbage collection of state
要求是实现失效分片清理&&垃圾回收。
这一部分通过前面提到的Handoff相关RPC实现,DoPollHandoff中已经介绍了sendHandoff RPC和sendHandoffDone RPC,在收到sendHandoffDone RPC时,说明自身向其他Group发送的shard已经被成功接受了,直接delete掉移交的key(shard)即可,并将对应的shard状态修改为serving。
Client requests during configuration changes
要求是在config发生变化时不阻塞Client的执行,即异步变更配置的shardkv。
Lab 4的初始要求是实现一个分片的分布式数据库,当配置发生变化时(即shard -> gid的映射变化),集群需要创建新的配置,原先负责这个shard的group不再负责这个shard,将shard迁移到新group后由新group负责,在迁移(Handoff)的过程中,不能接受客户端的请求。
直观实现是同步实现,即使用一个后台协程,这个协程定期更新配置,并计算配置变更,如果发现配置变更,则停止所有客户端请求和整个DoApply,移交切片并更新配置,等到所有切片准备完成后,才恢复客户端请求和DoApply协程。
这种方式效率十分低下,原因有如下两条
- 一个group可能会负责多个切片,当配置变更时,需要移交的切片可能只是一部分切片,如果客户端想要对未影响的shard进行操作,还需要等待整个handoff的完成
- 例子:由config1{ group1[shard2 shard3] group2[shard1 shard4 shard5] } -> config2{ group1[shard2 shard1 shard4] group2[shard3 shard5]}
- 这个配置变更只影响了group1的shard3和group2的shard1 shard4,在handoff过程中,如果想操作shard2,则需要等待handoff的完成,效率十分低下
- 一次配置的变更可能需要来自不同组的多个切片,而我们需要在一个切片完成handoff后可以立即执行客户端的操作,无需等待
- 还是上面的例子,在group1收到shard1后,客户端想要对shard1进行操作,必须要等到剩下的shard4进行handoff后才能操作,效率低下,我们需要让单个shard移交成功后立即就可以执行客户端命令
因此,需要完成配置更新,分片移交,分片恢复三个阶段的全异步化。
- 当检测到配置更新时,仅仅停止需要同步的切片,不能阻塞客户端请求和DoApply循环
- 移交单个Shard后需要立即恢复对该Shard的服务
常见的同步方法有拉切片,即系统检测到配置更新时,由新被分配的某个切片的组向切片所在原组去Pull(拉取)切片,博客采用了推切片的方法,与拉切片相反,当系统检测到配置更新时,由需要移交shard的组向需要接收shard的groups Push(推送)切片。
流程(大部分已经在前面介绍)
- 更新配置,这一流程对应结构图中的DoUpdateConfig
- leader定期拉取最新的配置,发现拉取配置的Num比本地配置大且所有分片都处于serving状态,调用Raft层的Start
- Raft层同步完成并提交最新配置给server 进行apply,server需要计算出需要移交的分片,并更新分片的状态,将需要移交的分片进行handoff(传递到handoffCh管道中,以此实现异步)
- 移交分片
- 通过DoPollHandoff,将各个group中handoffCh的数据提取并转发(通过RPC)
- 接收到handoff RPC的组的leader调用Start,成功后向原组发送handoffDone消息(通过RPC)
- 每个节点的DoApply收到handoff的消息后,根据参数更新自己的kv database
- 分片恢复
- 当原组的leader收到handoffDone消息后,调用Raft Start进行同步
- Raft同步完成交给server apply时,server清理对应的key(Challenge 1),并将分片恢复为正常状态serving,为下一轮reconfiguration作准备。
Q1 分片状态
除了Config中的Shard->Gid的映射关系,还需要给每个Shard设置当前状态,这里设计采用了三个状态,分别为Serving,Pushing,Pulling,采用一个额外的ShardState数组进行设置。
1 | type ShardKV struct { |
Q2 RPC消息
两种RPC消息,Handoff RPC和HandoffDone RPC,只用一种RPC是不能处理发送RPC节点宕机的情况,可以参考问题场景部分。
Q3 持久化
Snapshot的过程发生在DoApply中,当执行完一条命令发现kv.rf.GetStateSize() >= kv.maxraftstate时,调用rf.Snapshot()进行快照。
同样在DoApply中,发现传入的命令是Snapshot类型,则调用rf.CondInstallSnapshot()进行Raft服务层的Snapshot安装,如果安装成功,则进行KV Server的Snapshot安装。
问题场景
P1

组100中某节点发起移交,随后该节点宕机,接收组完成更新后返回完成消息,由于原节点已经宕机,导致他无法向Raft发送移交完成的消息,造成死锁。
方法
前面提到的不能使用一种RPC的原因,本质上是一个节点需要对某个RPC回复进行Raft共识时,回复可能会被网络延迟太久以至于回复到达时已经不是leader了,无法调用Start。
因此可以使用多对RPC,实现中采用了两对,即HandoffDone的发送方group101会找到group100中的leader进行发送。
P2

组100向组101移交 [a, b] shard,随后该节点宕机,group101完成了更新并开始服务,已经有客户端开始请求a shard了,这时由于发送移交的节点宕机了,原组没有收到回复,新选举了leader重新发起移交,这时可能会出现应用已经移交过的config,造成状态回退。
方法
进行Handoff命令的去重即可,首先检查Handoff的Shard的状态,确保传输的shard都处于pushing状态,同时检查Handoff的Num是否处于最新状态。
P3

组100的某节点rf.Start(config)后宕机,恢复后开始并不是leader,因此从Raft层传来的需要apply的Config并不会触发handoff,从而丢失一次reconfiguration。
方法
在DoUpdateConfig中执行rf.Start(config)时,对config添加一个committer参数,当收到Raft层传来的需要apply的Config信息时,如果这个committer和本节点的编号匹配,则无视本节点可能不是leader,进行handoff操作。
Command去重
使用 SequeceNum 对消息进行去重(客户端的每个请求都要带 ClientId 和递增的 SequenceNum,且仅在服务器返回 OK 时递增 SequenceNum),使用 SequenceNum 机制去重请求,那么客户端必须只有一个 goroutine 访问 SequenceNum 这个状态(不能存在并发)。如果是 Clerk 这很容易做到,但是对于移交分片的服务器到服务器通信则需要额外的机制。博客使用了一个 handoffCh 通道和的一个常驻的 goroutine 协程来保证这点。
1 | func (kv *ShardKV) DoPollHandoff() { |
这里的handoffCh需要进行buffered,buffer大小为NShards。
LeaseRead with noop
这一部分完全参考博客实现,大佬太强了:)
由于读请求无需修改kv database,只需要简单的访问数据库返回数据即可,再向Raft层传输命令log进行同步操作花费太大,因此有许多方法进行优化,常见如下:
- LogRead
- ReadIndex
- LeaseRead
- FollowerRead
这里采用了LeaseRead的方式进行优化,即在优化后,每个leader在每一轮获得多数心跳返回后,设定一个租约lease,过期时间是发起这轮心跳开始的时间+一个固定时LeaseDuration,需要保证Leader在租约过期之前不会换主(LeaseDuration < ElectionTimeout),同时租约过期后本Leader不应该继续服务。
一个 Leader 在上任前会提交一个 noop,这可能会导致此前还未提交的条目被提交并应用。在这一过程中不能服务任何请求(包括只读请求),因为这中间的状态不能被外界观察到。我们可以通过引入一个额外的 leaseSyncing 状态并修改 GetState 的语义来实现这点限制:isleader = rf.state == Leader && !rf.leaseSyncing && time.Now().Before(rf.leaseEndAt)。leaseSyncing 在节点转为 Leader 并提交 noop 时置为 true,并仅当 commitIndex >= lastApplied 才关闭 leaseSyncing。
在客户端调用Get时,判断当前rf的状态,如果rf.state == Leader && !rf.leaseSyncing && time.Now().Before(rf.leaseEndAt),则可以直接返回kv数据库中的value,无需日志同步,因此实现了read only优化。