
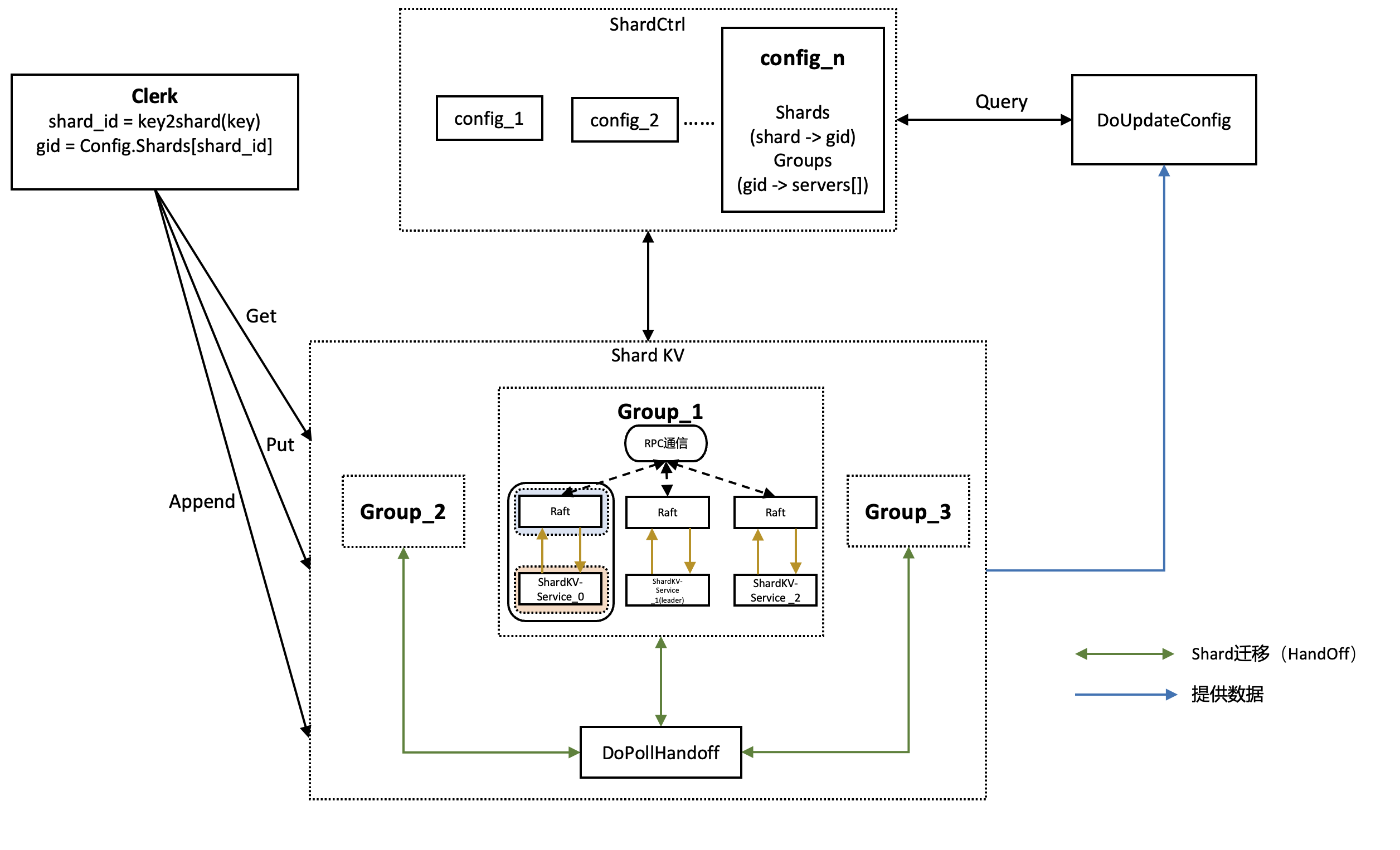
MIT6.824 2021 Lab4 Sharded KV Service
阅读本文前请先仔细阅读Lab 4相关实验要求并熟悉基础代码。
shard,即分片,一个shard是存储的kv键值对的一个子集,比如将所有开头字母为"a"的key value键值对映射作为一个shard
好处是可以在处理replica时,如果多次操作不同的shard可以并行处理,增加系统的吞吐量
在lab2和lab3中构建了一个异步Fault-tolerant KV数据库,实现了多节点之间的数据一致性,但是所有请求需要通过leader来处理,随着数据处理量越来越大,单一leader已经很难处理这种负载,因此在lab4中需要采用这种shard的方法,将数据按照某种方式分开存储到不同的集群上(group),降低单一集群的压力
lab4采用shard方法进行数据的划分,将不同数据划分到不同的shard上(shard之间不相交且并集为全集),再将各个shard分配到集群(groups)中,同一个阶段这样的shard与groups的对应关系称为一个配置(config)
随着时间的推移和数据的增加,shard需要在各个group之间进行迁移,lab4的主要挑战是在config更 ...

GPU相关
本文主要是自己对于GPU相关知识的总结,以Nvidia系列GPU为主,具体的架构和编程相关可能会在之后写cuda内容的时候介绍。
GPU发展历程
早期阶段(1980年代): 最初,GPU(Graphic Processing Unit)主要用于处理简单的2D图形,用于显示计算机屏幕上的图像。这些早期的GPU是图形加速卡的一部分,用于图形用户界面(GUI)操作和基本的图形渲染。
3D加速的兴起(1990年代): 随着电脑游戏和3D图形应用的兴起,GPU逐渐开始支持3D图形加速。3D加速卡开始崭露头角,提供更快的三维图形处理和渲染。NVIDIA和ATI(后来被AMD收购)等公司在这个时期推出了一系列创新的产品。
通用计算(2000年代): GPU不再仅限于图形处理,而是开始进入通用计算领域。CUDA(NVIDIA的并行计算架构)和OpenCL等技术使开发者能够利用GPU的并行处理能力执行更广泛的计算任务,如科学计算、数据分析和人工智能。
深度学习和人工智能(2010年代至今): GPU在深度学习和人工智能领域的发展迅速。由于深度学习模型对大量数据和大规模并行处理的需求,GPU的并行计算 ...
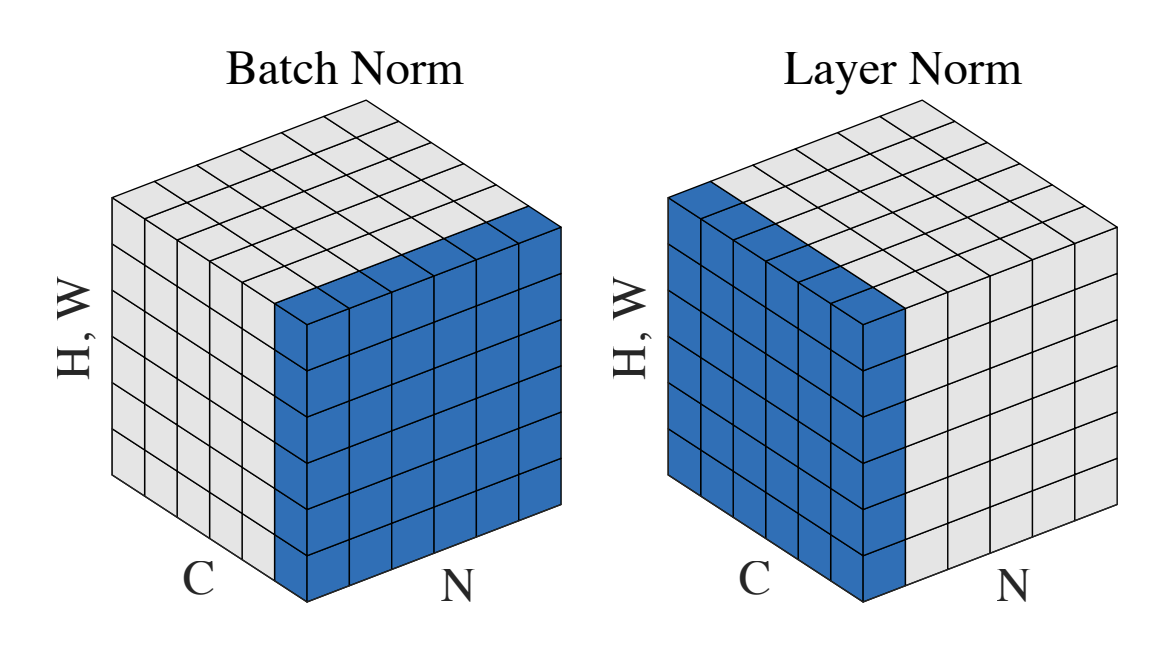
Batch Normalization和Layer Normalization
主要内容来自于李沐老师的视频,shine-lee的博客,本文主要是以上内容的总结
Batch Normalization(BN批量归一化)
为什么需要BN(Batch Normalization)?
训练深度网络时,反向传播时每一层的参数会更新,在之后的前向传播时前面层的输出数据会不断变化,会导致后续的层需要不断适应这种变化(这种现象被称为内部协变量偏移),内部协变量偏移会导致训练困难和结果的不稳定
神经网络层数比较深时,反向传播的梯度由后向前计算,如果不做任何处理,那么后面的梯度变化会更加的敏感,前面的梯度变化不明显(因为一般情况下梯度会是n个较小的数相乘,乘到后面可能变化非常不明显,即梯度消失,反之则是梯度爆炸)
神经网络中前面的layer可能提取一些表面信息,后面的layer根据这些信息来提取高级信息,因此前面的层发生变化对后面的层影响较大,为了避免过于震荡,需要将学习率设置的足够小,会导致收敛比较慢的问题
Batch Normalization来解决这个问题
方法
输入为一个batch BBB,其中每个元素为xi,i∈Bx_i, i \in Bxi,i∈B
获取小 ...
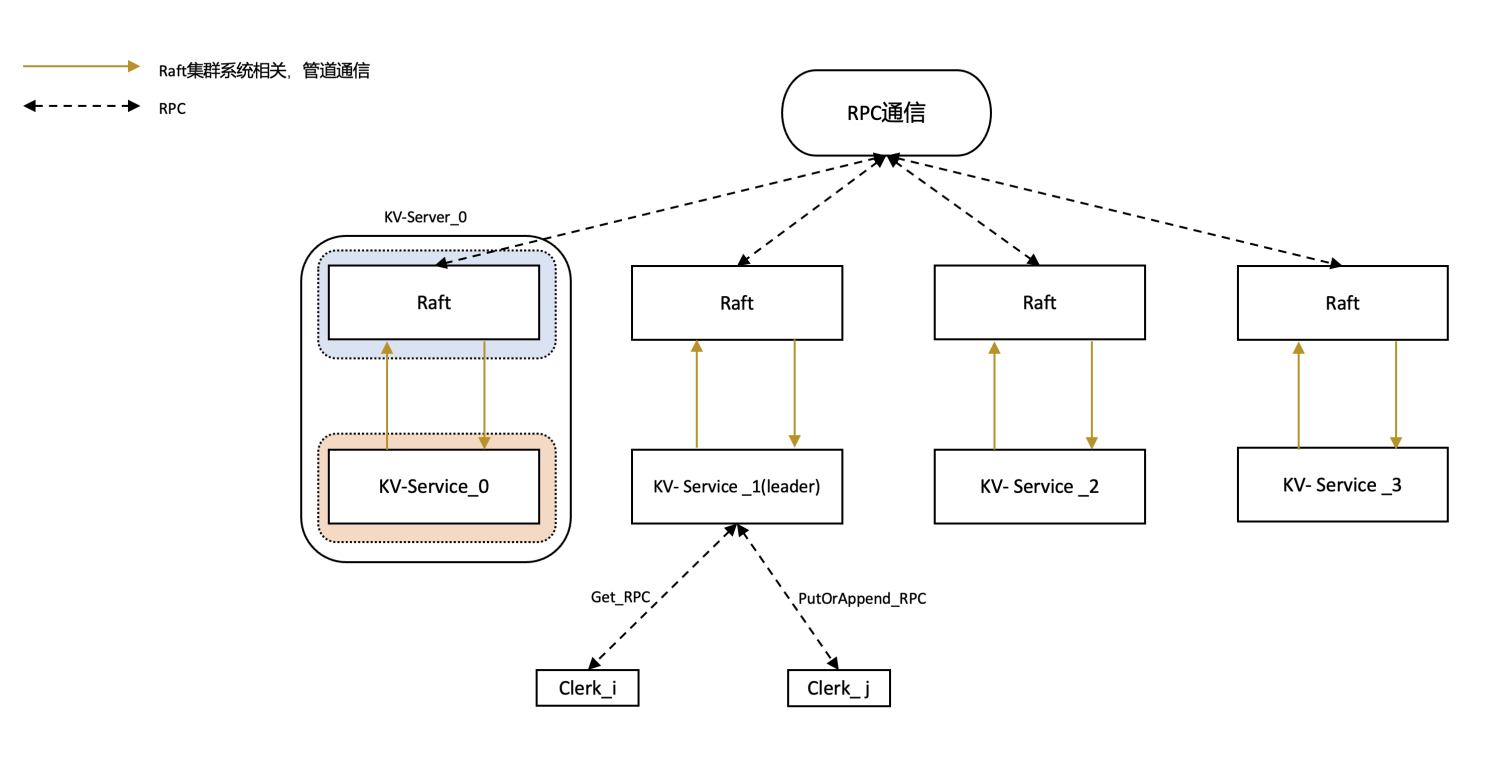
MIT6-824-2021-Lab3-KV-Raft
阅读本文前请先仔细阅读Lab 3相关实验要求并熟悉基础代码。
本文只提供相关实现思路,希望可以读者由此获得灵感。
Part 3A
实验说明
使用在lab2中编写的Raft实现fault-tolerant key-value DB集群
整个服务分为Clerk端和Server端,在Clerk端发出请求,在Server端处理请求并同步,再将结果返回给Clerk端
需要完成的请求
key value均为string类型
Get(key): 由Clerk调用,获取Server数据库中key值对应的value
Put(key, value): 由Clerk调用,将key-value键值对添加到Server数据库中,如果原来存在key键值对,则用新的覆盖旧的
Append(key, value): 由Clerk调用,将value添加到Server数据库对应key中,可以理解为字符串的拼接
在请求的基础上,结合lab2实现的Raft来完成多台Clerk的linearizability(线性一致性)
什么是linearizability?
图像来自于博客
上面给出两张图像,横轴代表时间,纵 ...
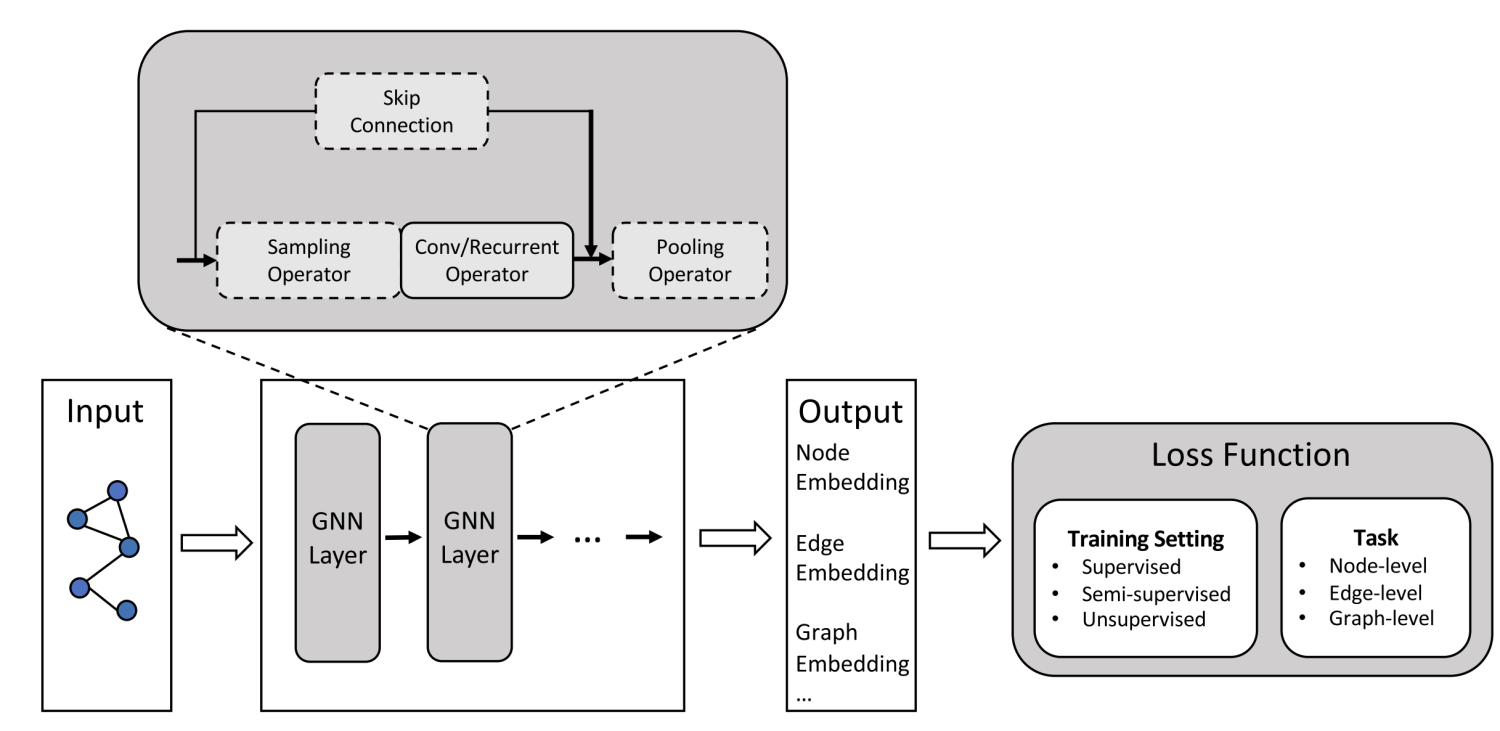
图神经网络极简总结
本文结构和内容主要参考自SivilTaram的博客和chhzh123的博客并加上自己的一些理解
图神经网络
数据常常可以被分类为欧式数据和非欧式数据。
欧式数据通常是我们在日常生活中遇到的最常见的数据类型,例如图像、音频和文本数据,这些数据由简单的序列或网格组成,较为结构化。
非欧式数据不属于传统的固定维度向量空间。例如,社交网络、知识图谱、复杂的文件系统都是非欧式数据。这类数据的关键特点是它们之间的关系不能简单地通过欧氏距离来度量,是非结构化的。
非欧式数据促使了图神经网络(Graph Neural Network, GNN)的出现和发展,GNN中所处理的图一般情况下指的是图论中的图,由若干节点以及连接节点的边所构成的数据结构。
输入:通常为一个Graph Network
输出:节点Label;新的Link;生成新图或者子图
对于图不同的任务
节点层面
Edge(Link)层面 (推荐系统)
整图方面(分子分类),子图方面(导航)
常见的任务
节点分类
Link预测
图分类
原理
给定一组图数据G(V,E)G(V, E)G(V,E),每个节点vvv在图GGG中都有一个 ...

Transformer简单笔记
主要来自于李宏毅老师的视频,在此之上进行了重点信息的总结。
Self-attention
对于神经网络的输入,可能是一个vector或者一组vector,例如输入是一句话,可以将每个词处理后作为一组vector输入到网络中。
上图是简单版本Self-attention的使用
有几个vector输入就有几个vector输出
Self-attention的输出考虑到了整个sequence
self-attention要做的事情简单来说,输入一组vector,根据vector之间的相关联程度,计算并输出一组output vector。
Self-attention输出的计算流程(以b1b^1b1为例)
第一步,计算输入向量a1a^1a1和其他向量相关程度alphaalphaalpha
如何计算任意两两vector之间的alphaalphaalpha
常用方法如下,一般采用Dot-product
以计算alpha1,i′alpha'_{1,i}alpha1,i′为例,首先拿WqW^qWq矩阵和输入向量a1a^1a1相乘获得中间矩阵q1q^1q1
再拿WkW^ ...

Git常见命令&&流程
个人自用
git clone 仓库
git checkout -b my-feature
切换到需要修改的分支
修改代码
git diff
查看当前修改后的代码与原来my-feature中的代码有哪些区别
git add xxx
将代码添加到暂存区
git commit -m “xxx”
[Feature]: New module or features.
[Bugfix]: Fix something.
[Refactor]: Style check.
git push origin my-feature
将本地my-feature分支推送到remote的my-feature分支,如果没有则自动创建
push完成后,准备合并branch到main中(这个过程是pull request, PR)
squash and merge
删除remote(主仓库)中的my-feature
git branch -D my-feature(一般不删除)
删除local branch
git pull origin master
拉去主仓库中的最新更新 ...
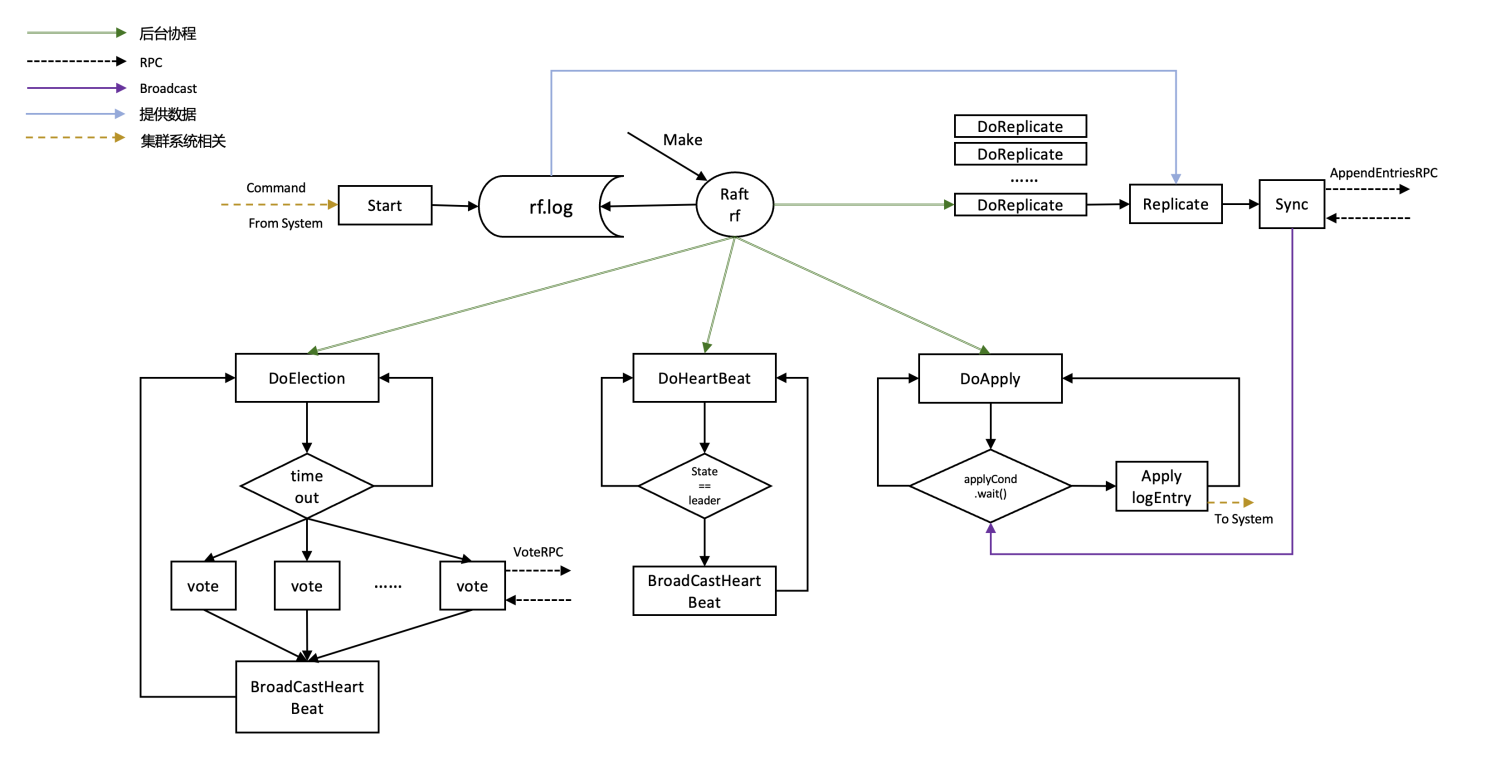
MIT6-824-2021-Lab2-Raft-Part-2C&&2D
阅读本文前请先仔细阅读Lab 2Part 2C && 2D相关实验要求并熟悉基础代码。
本文只提供相关实现思路,希望可以读者由此获得灵感。
Part 2C
2C实验说明
在raft每次更新重要信息后,对这些信息进行持久化保存
Test中某个server crash掉后,重新启动可以通过先前保存的持久化数据进行恢复
设计概述
在Part 2B实现的较为完备的情况下,Part 2C是比较简单的,只需要根据提示完成persist(), readPersist()函数,并在Make初始化过程中调用readPersist,关键信息更新时调用persist即可。
架构图可继续参考前文。
实现
根据论文中提供的信息,我们需要对term, votedFor, log进行持久化。
123456789101112131415161718192021222324252627282930313233343536// save Raft's persistent state to stable storage,// where it can later be retrieved a ...
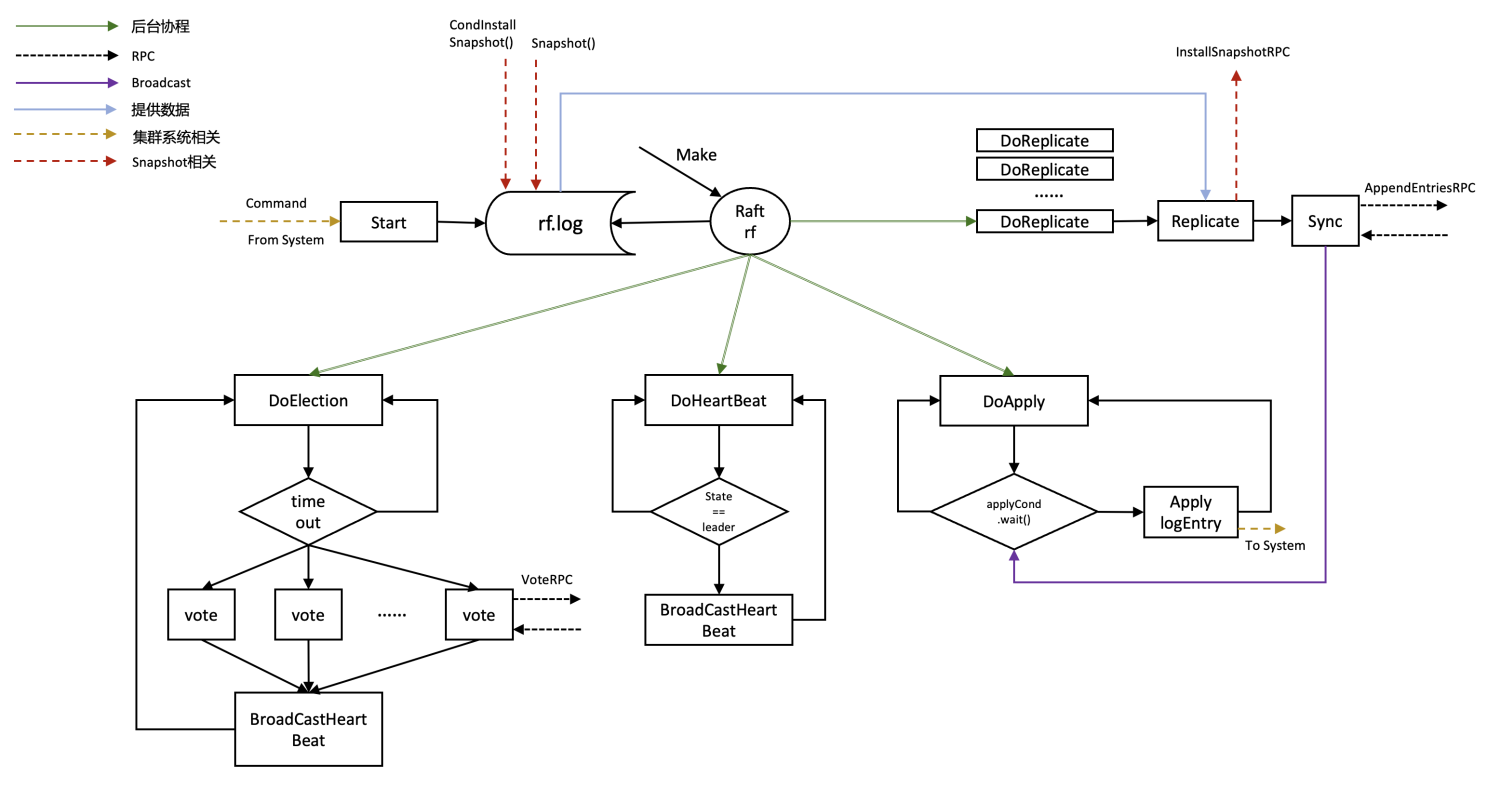
MIT6-824-2021-Lab2-Raft-Part-2B
从本次lab改用了2021版本的实验,后续的内容更加丰富,并对lab 2a的代码进行了重构,放弃了leader candidate follower明确划分的模式
阅读本文前请先仔细阅读Lab 2Part 2B相关实验要求并熟悉基础代码。
本文只提供相关实现思路,希望可以读者由此获得灵感。
2B实验说明
实现leader和follower之间的log entries的插入和更新
保证leader和follower之间的log一致
Test分析
在test构建系统的过程中调用了Make函数,其中applyCh是raft向系统传送msg的通道,用来更新cfg中的各个raft中的logs信息,应用指令(apply)可以看做向applyCh中写入信息。
后续的test通过检查cfg中的log是否一致来判断编写的程序是否正确。
cfg.nCommitted(index)返回两个参数,1多少个server认为编号为index的log entry被commited了,2被commited的命令
cfg.ones()在十秒内遍历全部的server,找到leader并Start(启动一个命令) ...
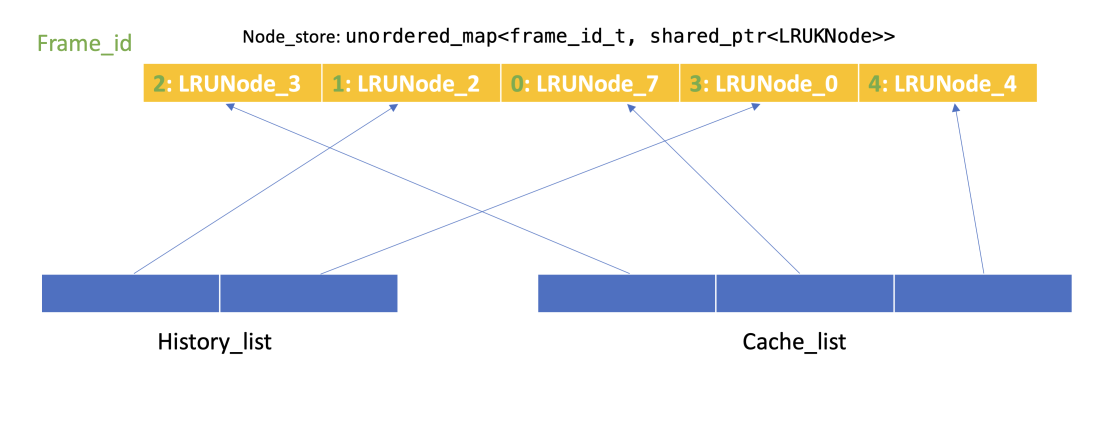
CMU15-445 2023 Spring Proj1 Buffer Pool
实验说明
实验主页https://15445.courses.cs.cmu.edu/spring2023/project1/
本次实验主要完成buffer pool(缓存池)
缓存池是用来在主存和磁盘之间移动物理页(physical page)的工具
该部分对于数据库管理系统(DBMS)的其他部分来说透明,举例来说,DBMS要求使用一个独有的page_id,buffer pool则帮DBMS获取这个page,不需要知道这个page一开始是否在主存中或者是从disk中取到主存再返回给DBMS的
Task #1 - LRU-K Replacement Policy
Task分析
需要使用LRU-K策略来实现frame的换入和换出。
普通的LRU策略是当replacer的缓存池的大小满了(这里是curr_size == replacer_size)后需要将其中最长时间没有访问的给替换出去。
LRU-K相对于LRU缓解了缓存污染的问题。
LRU缓存污染:偶发性的,周期性的批量操作会导致LRU cache的命中率急剧下降,这时缓存中的数据大部分都不是热点数据
如何确定K?K增大,命中 ...