MIT6-824-2021-Lab2-Raft-Part-2B
从本次lab改用了2021版本的实验,后续的内容更加丰富,并对lab 2a的代码进行了重构,放弃了leader candidate follower明确划分的模式
阅读本文前请先仔细阅读Lab 2Part 2B相关实验要求并熟悉基础代码。
本文只提供相关实现思路,希望可以读者由此获得灵感。
2B实验说明
- 实现leader和follower之间的log entries的插入和更新
- 保证leader和follower之间的log一致
Test分析
在test构建系统的过程中调用了Make函数,其中applyCh是raft向系统传送msg的通道,用来更新cfg中的各个raft中的logs信息,应用指令(apply)可以看做向applyCh中写入信息。
后续的test通过检查cfg中的log是否一致来判断编写的程序是否正确。
- cfg.nCommitted(index)返回两个参数,1多少个server认为编号为index的log entry被commited了,2被commited的命令
- cfg.ones()在十秒内遍历全部的server,找到leader并Start(启动一个命令),返回该命令的log index,当前的term和是否是leader,然后检查在2s之内这个命令是否被成功提交给大多数server
- rf.Start()的作用是启动新日志写入
- cfg.crash1(i)直接kill掉对应的server
- cfg.disconnect(i)将第i个server从集群系统中断开连接,但是server本身并没有被kill掉
- 在leader接收到超过半数的follower commit了对应的log,leader自身开始apply 对应的log,leader apply后通过心跳再提示follower apply对应的log,log一致性检查在cfg.applier中
设计概述
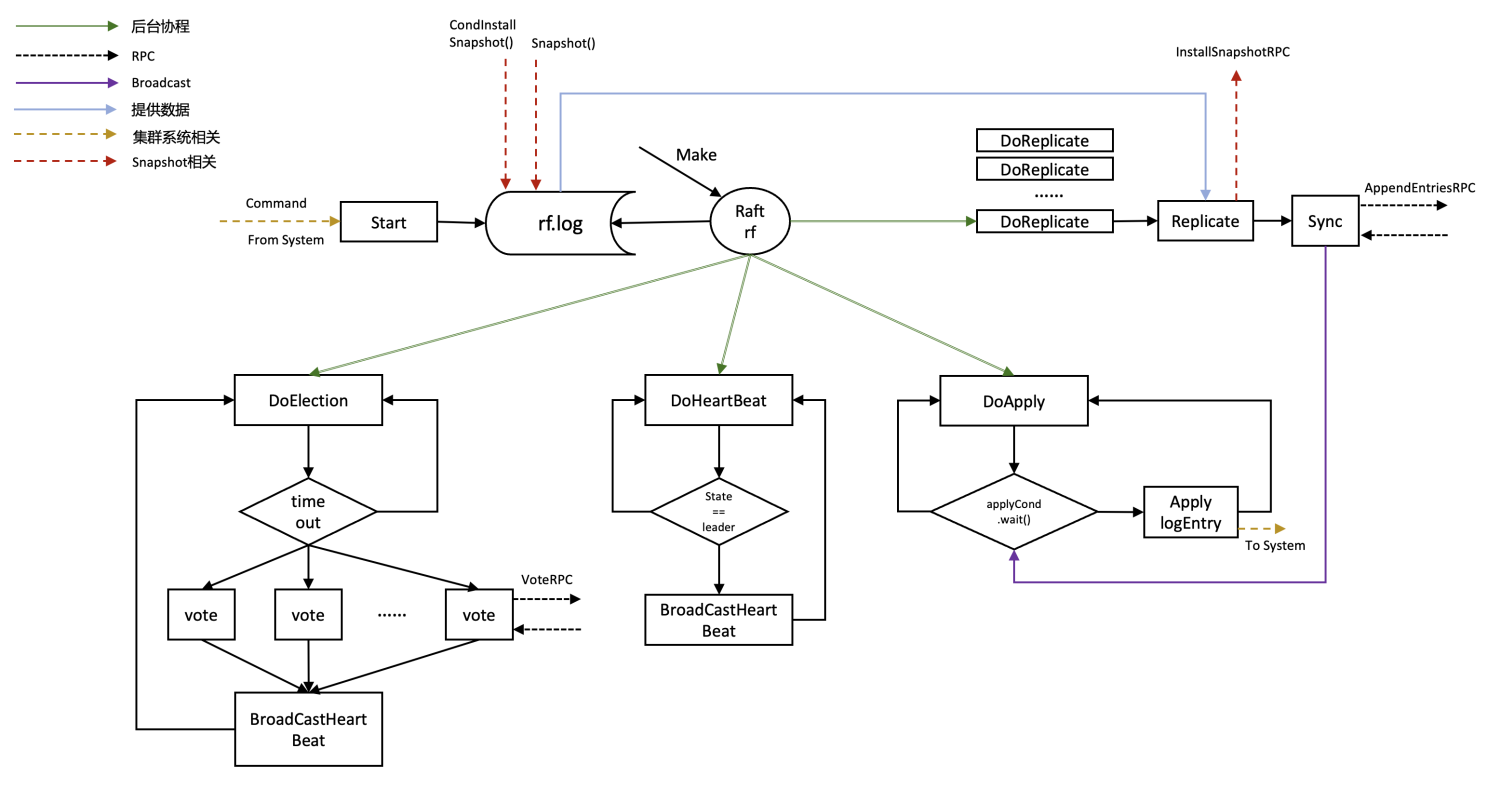
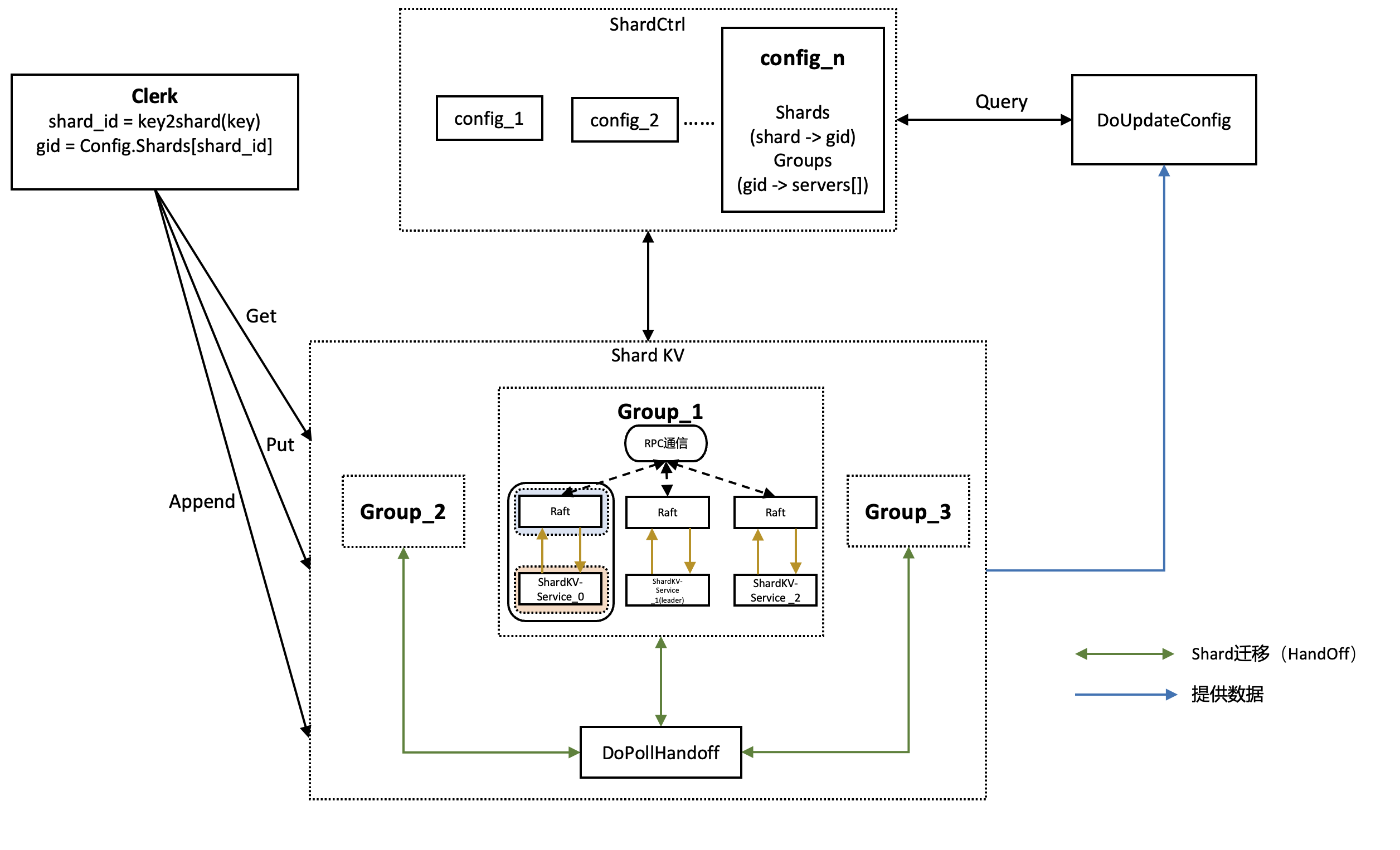
架构图

结构说明
- 通过Make在初始化时创建四个后台协程(其实是3+n个,DoReplicate的数量取决于集群中server的数量)
- DoElection负责选举
- DoHeartbeat负责心跳
- DoApply负责向集群apply日志
- DpReplicate负责leader与follower之间的日志同步
- 日志同步的主要流程
- leader收到客户端指令后(Start),将指令作为一个新条目(entry)追加到日志中
- 一条LogEntry有三个参数:cmd-指令,term-指令的任期号,index-日志号。
- leader通过AppendEntries RPC并行的发送日志到follower,当有超过半数的follower回复后(commit),leader就可以在本地执行该指令(apply)并把结果返回给客户端。
- 注意区别commit和apply,commit是指确定日志已经复制到半数节点,而apply是日志应用到状态机,因此可以理解为applyIndex<=commitIndex
- leader收到客户端指令后(Start),将指令作为一个新条目(entry)追加到日志中
分析
整个过程中follower可能会和leader无法保持一致如下图所示

- 三类原因以及解决方式
- follower由于某些延误没有给leader响应,leader会不断重发追加条目请求(AppendEntries RPC),哪怕leader已经回复了客户端(日志已经apply)
- follower崩溃后恢复,这时Raft追加条目的一致性检查
- 一致性检查:leader在每一个发往follower的追加条目RPC中,放入前一个日志条目的索引位置(prevLogIndex)和任期号(prevLogTerm),如果follower在他的日志中找不到前一个日志,follower会拒绝此日志,leader会重新再发送前一个日志,这样逐渐向前定位到follower第一个缺失的日志
- leader宕机,崩溃的leader可能复制了日志到部分follower,而新选择的leader可能不具备这些日志,这样导致部分follower中的日志和新leader的日志不相同
- Raft在这种情况下,leader会强制follower复制他的日志来解决不一致的问题
- 两者冲突的日志会被新的leader日志覆盖

- 如果leaderCommit>commitIndex,则commitIndex=min(leaderCommit, index of last new entry)
安全性相关问题
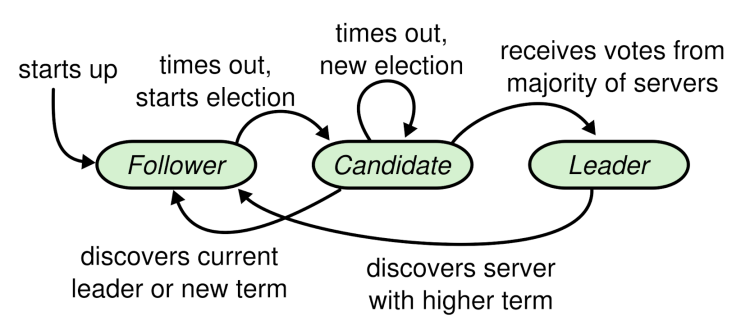
- leader宕机:选举限制
- 一个follower落后leader若干日志,但是没有遗漏整个任期
- 下次选举中,仍然有可能当选leader,当选新leader后永远无法补上之前缺失的那部分日志,造成状态机之间的不一致
- 增加一个限制,确保被选出来的leader一定包含之前各任期内所有被提交的日志条目
- 通过RequestVote RPC后俩参数

- 如果投票者自己的日志比candidate还新,他会拒绝掉该投票请求
- 通过比较两份日志中最后一条日志条目的索引和任期号来定义谁的日志比较新
- 任期号不同,大的新
- 任期号相同,日志长的新
- leader宕机:新leader是否提交之前任期内的日志条目
- 一旦当前任期内某个日志条目已经存储到过半服务器节点上,leader就知道当前日志可以被提交了
- follower的提交如何被触发?raft中的提交为单点提交
- 通过AppendEntries RPC中的leaderCommit 参数,表示leader提交到那个日志了,从而自己也可以应用提交到这个日志
- raft永远不会通过计算副本数目的方式来提交之前任期内的日志条目,只有自己任期内的日志才能通过计算副本数目来提交,因为可以确认自己当前的任期号是最大的
- follower和candidate宕机
- 如果这俩宕机,后续发送给他们的RPC都会失败
- raft通过无限的重试来处理这种失败,如果崩溃的机器重启,那么这些RPC就会成功完成
Test中的Figure 8问题
解释可以参考https://zhuanlan.zhihu.com/p/369989974
解决方式
- leader只能够提交自己任期内的log entry,禁止提交非自己任期内的log entry
实现
1 | func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) |
- Success = false的情况
- args.Term < rf.term
- log不匹配
- 流程
- 获取锁
- 检查args.Term和rf.Term
- 如果args.Term < rf.term则失败返回,反之则更新心跳,Term和state
- 更新term为args.Term,更新state为Follower
- 进行日志匹配判定,不匹配则失败返回冲突的index,匹配则进行log合并,持久化
- 判定是否需要更新commitIndex
- 如果需要更新则使用min(args.LeaderCommit, rf.LogTail().Index)更新,防止日志回滚
- 广播apply命令
- success = true
1 | func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) |
- success = false 的情况
- args.Term < rf.term
- 投过票了
- args中的日志旧
- 流程
- 获取锁
- 检查args.Term和rf.Term
- 如果args.Term < rf.term则失败返回
- 更新term为args.Term,更新state为Follower
- 如果检查条件为可以投票( (没有投过票||投票给同一个人) && args的日志新 )
- 更新心跳,更新rf.voteFor,更新success,持久化
- 不可以投票则success=false返回
- 如何确定args中log新于rf中log
- 判断args log尾部entry的Term和rf log尾部entry的Term
- 大于则新
- 等于则判断尾部的entry Index,大于等于则新
- 其余为旧
- 判断args log尾部entry的Term和rf log尾部entry的Term
1 | func (rf *Raft) DoElection() |
在Make阶段创建的后台协程,只要rf没有被kill掉就一直运行
流程
- 获取锁
- 判断当前是否是leader,如果是则释放锁continue
- 判断接受心跳时间是否超过ElectionTimeout,如果没有,则解锁进行下一次循环
- 超时,遍历其他server投票请求投票RPC进行选举
- 选举成功(收到成功的回复数 > num of server / 2),更新自身状态为leader,初始化自身nextIndex和matchIndex,并BroadcastHeartbeat广播一次心跳
- 完成上述操作后继续Election
1 | func (rf *Raft) BroadcastHeartbeat() |
广播心跳
- 使用go协程向其他server 进行Replicate操作(复制日志)
1 | func (rf *Raft) Replicate(server int) |
复制日志,主要是获取相关参数,传入Sync进行
流程
- 获取锁
- 判断当前状态是否是leader,只有leader才可以进行Replicate操作
- 获取当前rf.nextIndex[server],将位于nextIndex到rf.LogTail之间的logEntry作为参数Entries构建AppendEntriesArgs
- 解锁后进行Sync操作
1 | func (rf *Raft) Sync(server int, args *AppendEntriesArgs) |
同步操作,通过sendAppendEntries来实现leader和follower之间的日志同步
流程
- 向server发送sendAppendEntries并获得reply AppendEntriesReply
- 获取锁
- 判断rf.term 是否等于 args.Term,不相等说明leader已经不是leader,解锁并返回
- 判断rf.term和reply.Term,若reply.Term > rf.term,说明leader也已经过期,重设rf的term和state
- reply.Success == true
- len(args.Entries) == 0,说明是发送的是单纯心跳,不用做任何处理直接返回
- 获取logTailIndex := LogTail(args.Entries).Index,以此更新nextIndex和matchIndex
- 遍历从rf.commitIndex到logTailIndex,找到最大的超过半数节点match的Index,以此Index更新rf.commitIndex,因为只有在大多数节点都复制了日志后,且日志的任期和leader的任期一致,才能提交日志(test中的figure 8)
- 当rf.commitIndex > rf.lastApplied时,进行applyCond.Broadcast(),提醒DoApply协程需要进行apply操作了
- reply.Success == false
- 更新rf.nextIndex 和 rf.matchIndex
1 | func (rf *Raft) DoApply(applyCh chan ApplyMsg) |
后台协程,用来apply log日志,通过条件变量rf.applyCond来实现协程的唤醒
流程
- 获取rf.applyCond.L.Lock() (在go中,条件变量调用wait方法时必须要持有锁L.Lock())
- for循环,如果rf kill了则退出并解除相关锁
- 判断当前是否需要apply (rf.lastApplied < rf.commitIndex可以认为需要apply)
- 如果不需要则调用wait方法休眠
- 需要apply,则获取需要apply的log即rf.GetLogAtIndex(rf.lastApplied),以该log的信息为参数传入到applyCh
测试
编写脚本测试500次,全部通过。

注意
- 尽量不要简单的将log entry在rf.log中的位置直接作为index,推荐将index单独编入entry结构体中,不然后续的lab 2C 2D会非常痛苦,同理不推荐直接根据entry在log中的位置进行各种操作,可以编写根据logIndex获取对应log entry的函数来进行处理
- 需要仔细理解Figure 8的含义,注意在更新commitIndex时日志回滚的问题
参考内容 && 致谢
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Hongwen Xin's Blog!