MIT6-824-2021-Lab3-KV-Raft
阅读本文前请先仔细阅读Lab 3相关实验要求并熟悉基础代码。
本文只提供相关实现思路,希望可以读者由此获得灵感。
Part 3A
实验说明
- 使用在lab2中编写的Raft实现fault-tolerant key-value DB集群
- 整个服务分为Clerk端和Server端,在Clerk端发出请求,在Server端处理请求并同步,再将结果返回给Clerk端
- 需要完成的请求
- key value均为string类型
- Get(key): 由Clerk调用,获取Server数据库中key值对应的value
- Put(key, value): 由Clerk调用,将key-value键值对添加到Server数据库中,如果原来存在key键值对,则用新的覆盖旧的
- Append(key, value): 由Clerk调用,将value添加到Server数据库对应key中,可以理解为字符串的拼接
- 在请求的基础上,结合lab2实现的Raft来完成多台Clerk的linearizability(线性一致性)
- 什么是linearizability?
- 图像来自于博客


- 上面给出两张图像,横轴代表时间,纵轴代表Client
- 第一张图满足linearizability,而第二张图不满足linearizability
- 观察Get的结果,Client 4 Get返回0,Client 3 Get返回1,则按照图一橙色线作为操作完成的时间点即(linearization point),可以得到正确的结果,而图二无论怎么切割都无法使得先Get 1后Get 0
- Test分析
- TestBasic3A:正常情况下,保证单个 Client 命令能执行成功,保证 5 台 KVServer 日志一致。
- TestUnreliable3A:处理 RPC 调用超时,重试请求。
- TestOnePartition3A:处理多台 Client 和多台 Server 都发生网络分区的情况。
- TestPersistPartitionUnreliableLinearizable3A:在节点失效、网络不可靠的环境中保证线性一致性。
设计概述
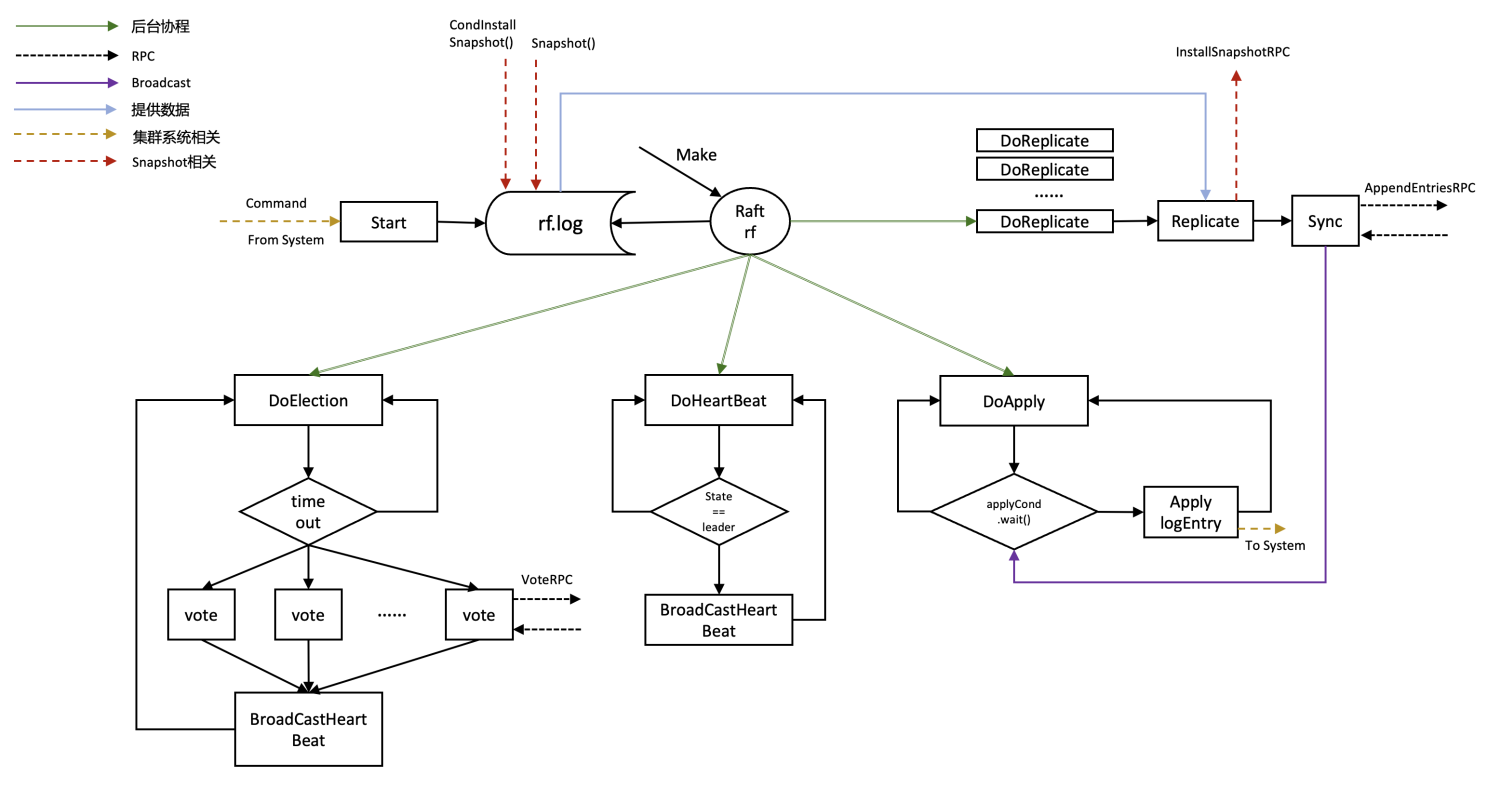
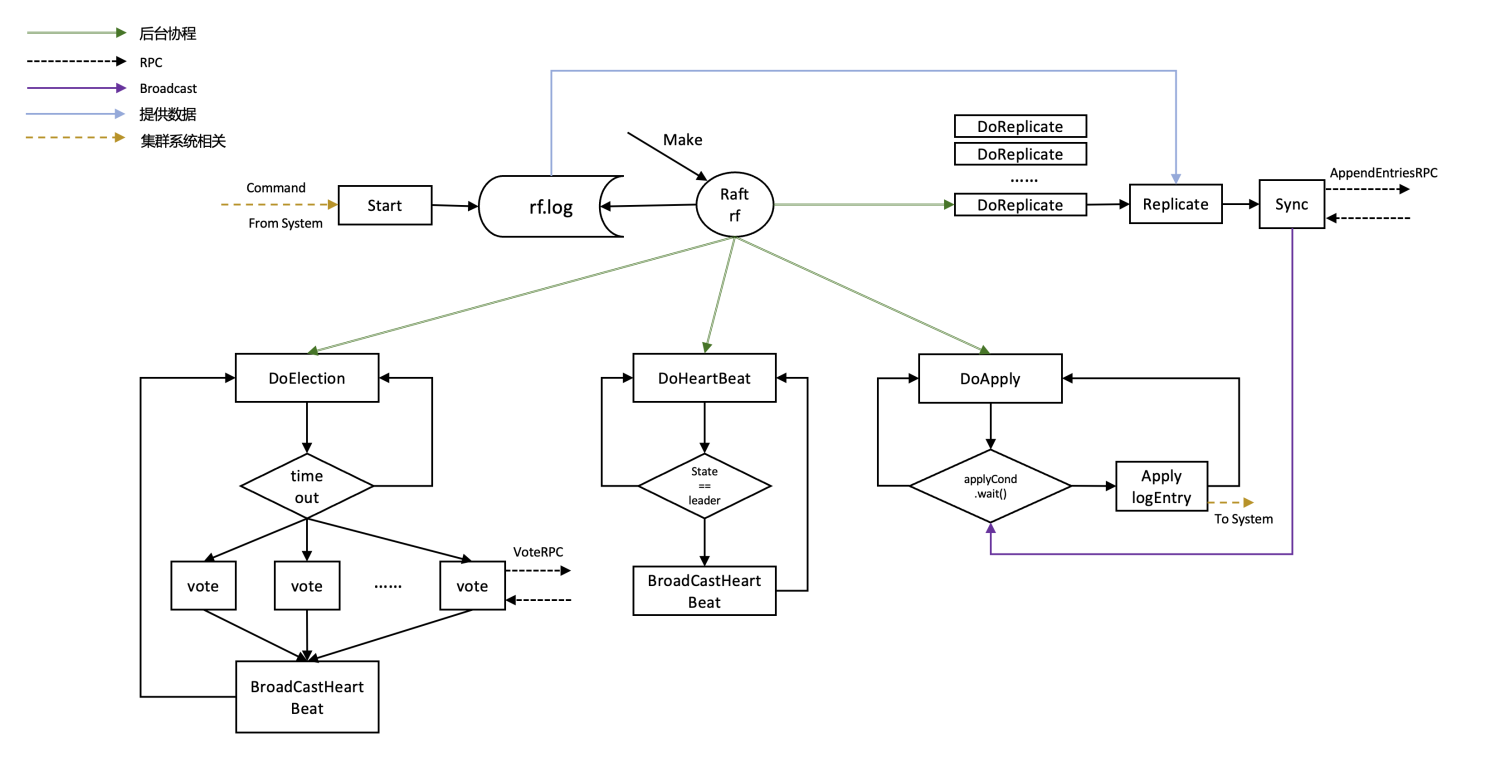
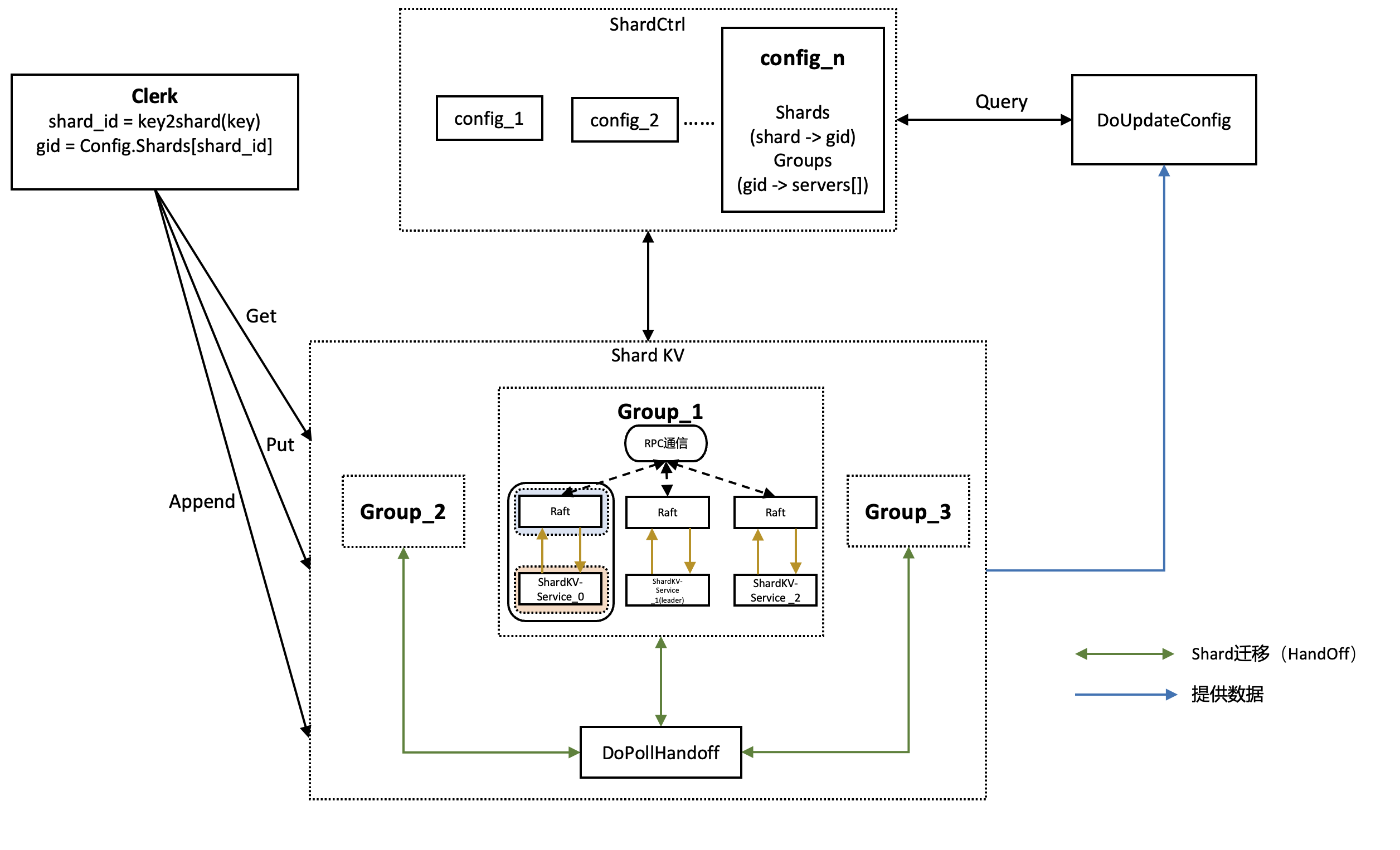
官方diagram,个人感觉不是特别清晰,根据自己的实现重新画了一个简化版本的



Clerk
- Clerk自身参数除了默认的servers,还需要定义自身的Clerk id(cid)和当前系统中的leader id
- Clerk负责向对应的KV-Server传递Command信息,传递过程使用RPC进行通信,因此需要定义一些RPC请求回复变量
- 对于Get方法,需要传递给KV-Server的只有key,返回信息则是key对应的value
- 对于Put和Append方法,合并为PutAppend方法,传递的参数除了key,value外,还需要Clerk id和Request id(用来唯一定义这条Command)
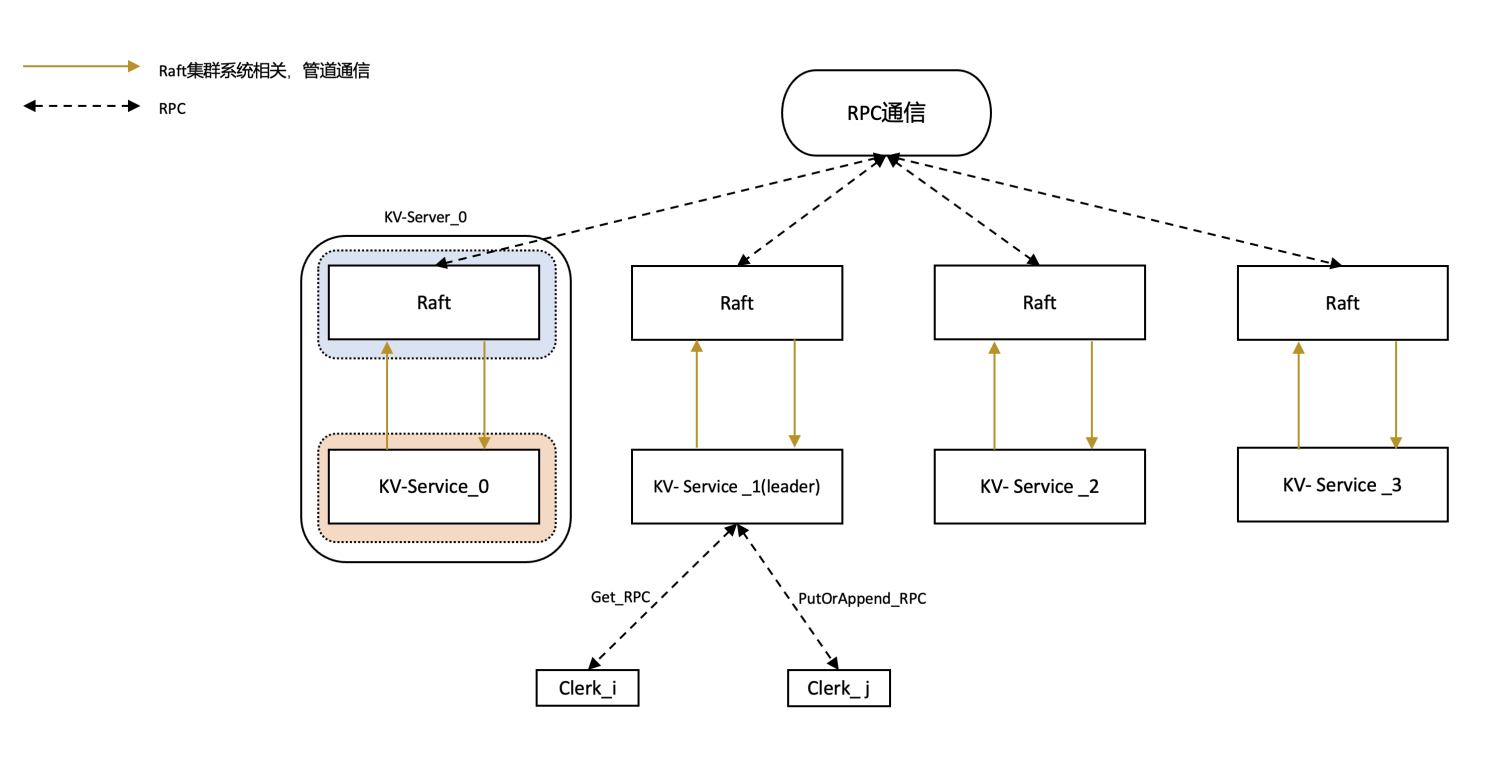
KV-Server
- Make时创建一个后台协程DoApply,一直监听Raft系统向自己传输的需要apply的Command
- 注意,并不是监听Clerk向自己发送的Command!!!
- 因为在Clerk向自身KV-Server发送相关Command时,Server本身是作为一个信息转发站,将Command信息先发送到Raft服务中,让集群中各个节点完成同步,集群同步后再通过管道将需要apply的Command发送到Server进行实际的apply
- 注意,并不是监听Clerk向自己发送的Command!!!
整体流程
- 首先通过各类Make方法构建整个系统
- 对于Client,通过rand方法生成自己的cid
- 用户操作客户端Clerk发起命令,以Put(key, value)为例
- 1 找到leader,并将参数通过RPC传递给leader对应KV-Server的PutAppend方法
- 2 该KV-Server使用管道将传递进来的参数继续传递给Raft系统,等待系统完成大多数commit并向KV-Server发送需要apply的Command(已经在lab2中完成),并为这个Command创建一个channel(Command Index -> channel 的映射),通过DoApply向这个channel发送信息来判断是否apply成功
- 如果等待超时,回到第一步
- 从管道中成功接收到信息,说明这条Command已经成功apply到KV系统中
- 3 KV-Server配置RPC reply信息并返回success
- 4 Clerk收到RPC的回复信息,并返回
- Server通过DoApply协程监听Raft系统向自己传输的需要apply的Command
- 从管道接收到需要apply的Command(以Put为例),如果Command valid,则更新kv.kv( kv.kv[args.Key] = args.Value ),并向刚才创建的channel发送成功的信息,证明已经完成了这条Command的apply
- 继续循环监听kv.applyCh
Fault-tolerance
- Raft相关fault已经在Lab 2中妥善处理,主要关注KV-Server的fault
- Server直接宕机(Lab 3B中使用Snapshot处理)
- Clerk和Server之间的RPC丢失问题(下面栗子来源于十一的博客)
- Client 向 Server 发送 Append(x, 1) 的请求
- Server 成功接收,Raft 层达成共识,应用至状态机。此时状态机状态 {x: 1}
- 由于网络原因,Server 向 Client 返回的结果丢失
- Client 苦苦等待,也没有收到 Server 返回的结果,于是超时重试。绕了一圈后又回到了这个 Server (此 Server 仍为 Leader)
- Client 又向 Server 发送 Append(x, 1) 的请求,Server 成功接收,Raft 层达成共识,应用至状态机。此时状态机状态 {x: 11}
- 这次 Server 成功向 Client 返回了结果。
- Client 成功收到了返回的结果,结束请求。然而原本的 Append(x, 1) 请求,造成了 Append(x, 11) 的后果。
出现上述问题的原因是Raft允许相同的command 传递给Server进行apply多次,因此我们需要在Server的服务中对传输的command去重。
方案
在Server中添加一个映射map kv.clc (means client latest command),所有Client对应的最新的一次操作,即Client -> Command的映射,在Server apply之前查看当前Client的上一次执行的最新命令是否和这次的相同,如果相同,说明是重复的命令,无需执行,这样可以避免命令apply多次的问题,用这种方式完成一定的Fault-tolerance。
注意
对于Clerk
- ReTry间隔设置为300毫秒
- 没有用到Lock
- 注意当前leader失效的情况,如果失效,我采用的是逐个寻找的方法
对于Server
- 也需要注意当前leader失效的情况,需要判断Server apply命令后leader是否发生变化
- 在操作map映射时需要注意Lock的使用,对于kv.kv即存储的键值对,个人没有使用Lock,因为每个Server都保存者自己的数据,没有竞争
Part 3B
实验说明
- 在3A中,Client Operation通过leader同步到其他的follwer中,同步过程使用Raft维护数据的一致性,随着Client Operation的增多,每个Server和对应的Raft服务不可能无休止的存储数据(kv.kv rf.log),因此需要Snapshot(快照)来压缩使用空间
- 如果之前Lab 2的Snapshot做到完备实现的话,3B是比较简单的
设计概述
- Raft的Snapshot已经在Lab 2中完成,但是还需要KV-Server传输相关数据保存至snapshot
- Client操作不涉及Snapshot
- 对于KV-Server需要保存什么?
- 生成快照时的数据库
- 3A中为了fault-tolerance所设置的map映射,即kv.clc,所有Client对应的最新的一次操作,避免Command的重复apply
- 什么时候需要生成Snapshot?
- DoApply一直在监听Raft传来的Command,当传来的Command合法,执行完成后发现kv.rf.GetStateSize() >= kv.maxraftstate && kv.maxraftstate != -1时,就需要进行Raft的Snapshot,调用Snapshot时不要忘记添加KV-Server需要保存的数据
- 什么时候需要安装Snapshot?
- DoApply一直在监听Raft传来的Command,当传来的Command不合法时,说明当前Server缺少内容,这时就需要CondInstallSnapshot进行Snapshot的安装

注意
- KV-Server的在初始化时需要readSnapshot,确保如果Server之前宕机的话可以恢复之前的状态
总结
- Lab 3A在Lab 2的基础上完成了一个异步Fault-tolerant Key-Value数据库,依靠底层 Raft 算法在节点崩溃重启甚至不可用、网络延迟丢包甚至分区的环境下,依旧对多个Client 保证数据的线性一致性
- Lab 3B则实现了实时监测Raft状态信息,阶段生成快照,当发现自身缺失信息时则安装快照,维持了数据的一致性
- 关于fault-tolerance,3A中利用一个映射保存Client和他上一次最新apply的命令来保证不会重复提交的问题,3B则是利用Snapshot进行Server的恢复,避免了机器宕机后造成的数据不一致问题
- Test时可能遇到超时的问题,考虑一下在Lab 2中Lock是否合理使用,不合理的Lock可能会导致争用异常激烈
参考内容 && 致谢
- raft论文 Sec 7 && 8
- wuYin的Github1
- wuYin的Github1
- sworduo的博客
- 十一的博客
- 谭新宇的博客
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Hongwen Xin's Blog!