MIT6-824-2021-Lab2-Raft-Part-2C&&2D
阅读本文前请先仔细阅读Lab 2Part 2C && 2D相关实验要求并熟悉基础代码。
本文只提供相关实现思路,希望可以读者由此获得灵感。
Part 2C
2C实验说明
- 在raft每次更新重要信息后,对这些信息进行持久化保存
- Test中某个server crash掉后,重新启动可以通过先前保存的持久化数据进行恢复
设计概述
在Part 2B实现的较为完备的情况下,Part 2C是比较简单的,只需要根据提示完成persist(), readPersist()函数,并在Make初始化过程中调用readPersist,关键信息更新时调用persist即可。
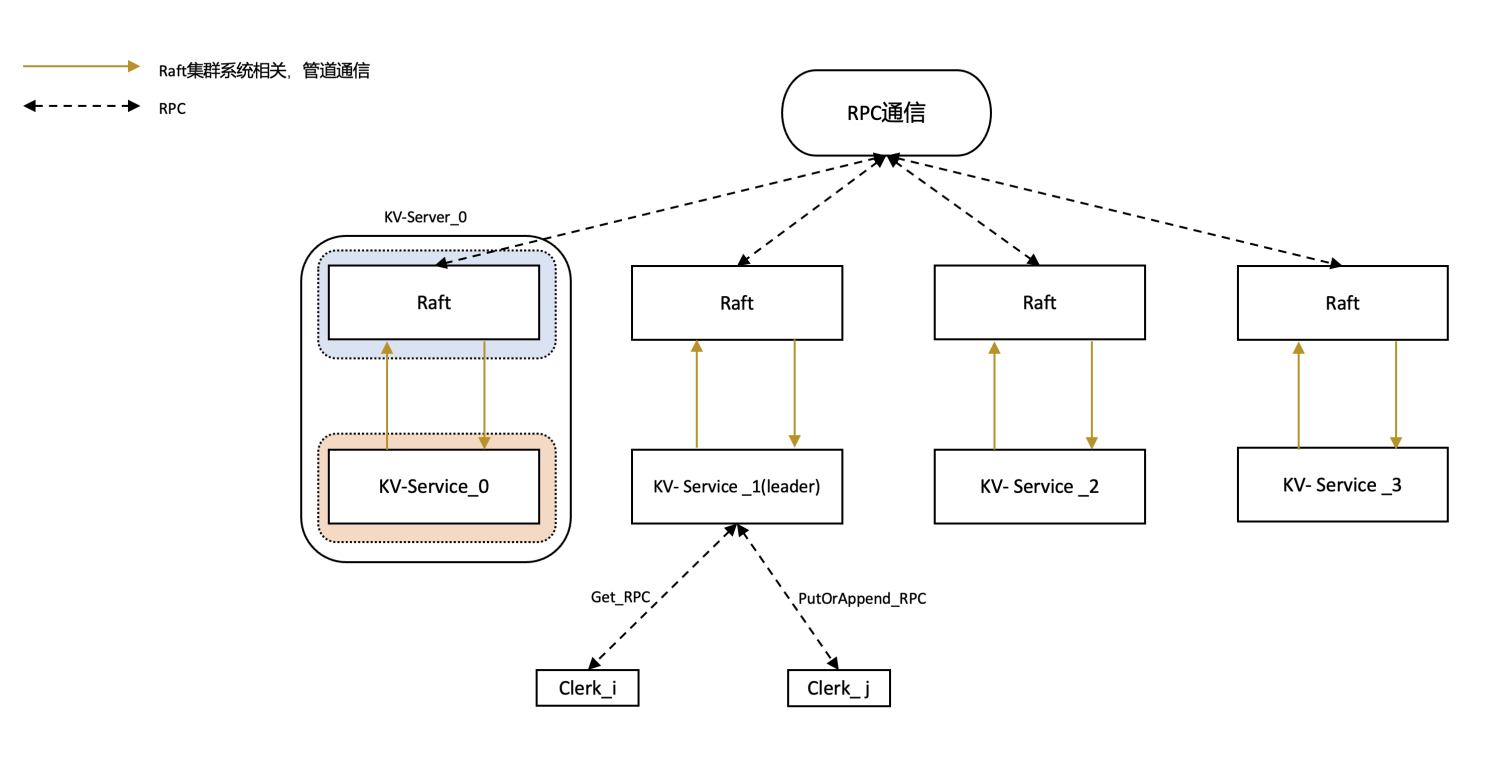
架构图可继续参考前文。
实现
根据论文中提供的信息,我们需要对term, votedFor, log进行持久化。
1 | // save Raft's persistent state to stable storage, |
只要server中这些变量发生变化,调用persist()保存信息即可,在这里的持久化并不是保存到disk上,而是通过persist()类保存在内存中,Test中仅仅crash server,并没有crash掉server 对应的persister,以此实现信息的持久化,实际的工程中不会这么去做。
注意
- 注意前文中的Figure 8问题,如果没有考虑完全会在2C中报错
Part 2D
2D实验说明
- raft server随着运行时间越来越长,保存的日志会越来越多,为了节约空间会做compaction(压缩)操作
- 压缩过程是将某一个状态之前的日志条目压缩为snapshot
- 当某个server落后于leader,且leader中该server的nextIndex所指示的log entry已经被leader压缩了,需要使用leader中的snapshot来更新server
设计概述
snapshot设计

- snapshot需要保存的信息
- LastIncludedIndex: Snapshot最后一个log entry的index,这个字段并不是real index,real index = LastIncludedIndex + logIndex,参考下图
- LastIncludedTerm: Snapshot最后一个log entry的term
- MachineState(Data): Snapshot中机器的快照数据
- LastIncludedIndex: Snapshot最后一个log entry的index,这个字段并不是real index,real index = LastIncludedIndex + logIndex,参考下图
- 需要实现的函数
- Snapshot()
- RPC相关,sendInstallSnapshot(), InstallSnapshot()
- 当leader发现某个server nextIndex已经被压缩在快照中,没法通过正常的AppendEntriesRPC进行同步,需要编写相关的RPC使得leader向集群发送对该server安装leader Snapshot的请求,并传递相关的参数
- CondInstallSnapshot(), 由集群调用,对目标server安装Snapshot

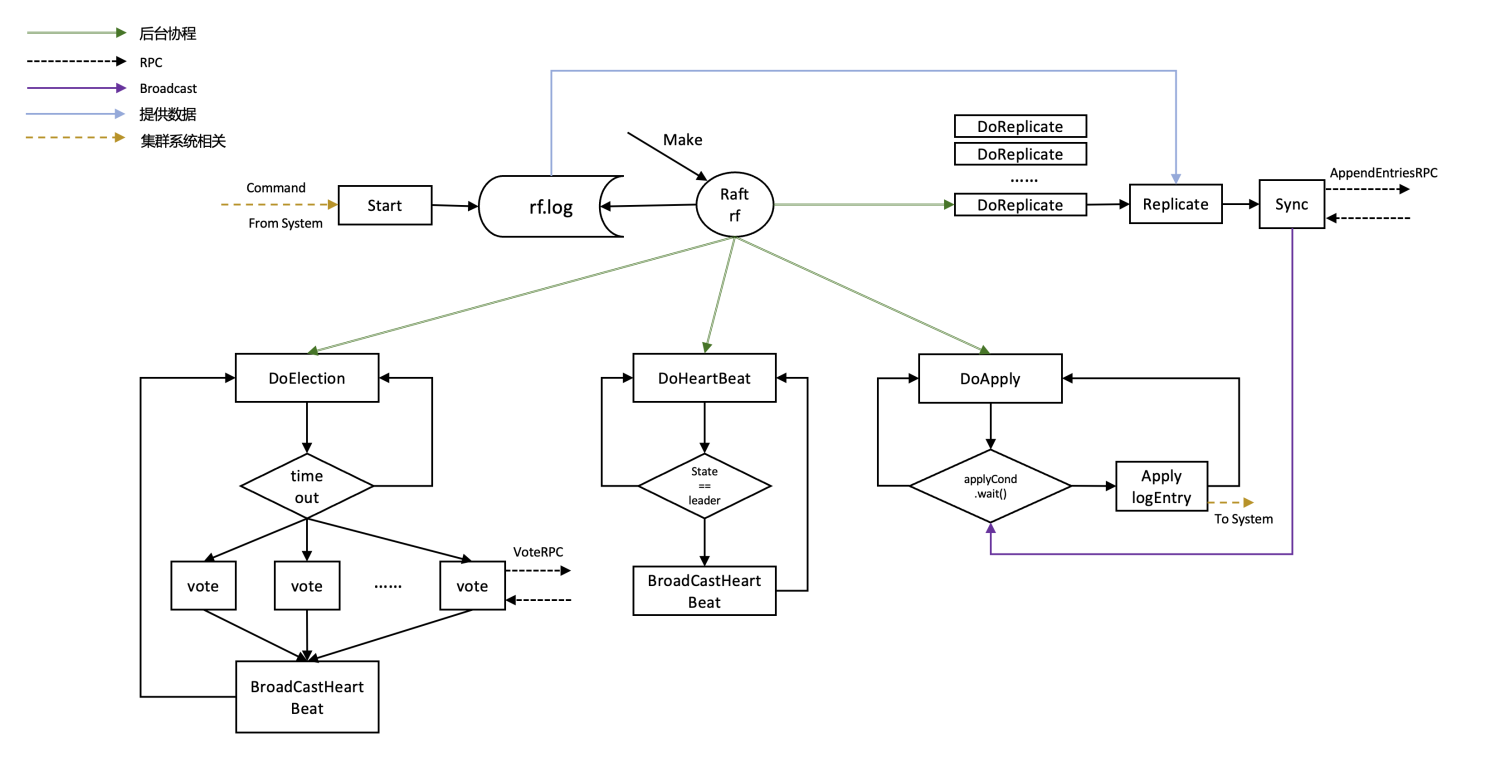
架构图

整体流程
- 如果当前server中log数据量超过存储极限,触发Snapshot(m.CommandIndex, w.Bytes()),触发过程发生在config.go中
- 传入参数为m.CommandIndex, w.Bytes()
- m.CommandIndex 表示一直压缩到logIndex == m.CommandIndex的log entry为止
- w.Bytes() 为传入的snapshot
- 传入参数为m.CommandIndex, w.Bytes()
- 如果当前leader在向其他follower复制日志(Replicate)的过程中发现某follower缺失log,且该follower对应nextIndex的log entry已经被leader压缩进snapshot中了,这时需要leader需要调用sendInstallSnapshot(), InstallSnapshot()来对该follower实现snapshot拷贝,然后该follower在下一个周期再进行正常的Replicate操作
- 简单来说
- leader发现某follower nextIndex对应的log缺失
- 发送包括LastIncludedIndex,LastIncludedTerm,Data等信息作为args的InstallSnapshotRPC
- 对应的follower收到InstallSnapshotRPC,根据传输过来的参数执行CondInstallSnapshot(),进行snapshot的安装
实现
1 | func (rf *Raft) Snapshot(index int, snapshot []byte) |
- 流程
- 获取锁
- 遍历自身的log,通过index找到对应的log entry,丢弃该log之前的全部log,并保存自身重要信息和snapshot
1 | func (rf *Raft) InstallSnapshot(args *InstallsnapshotArgs, reply *InstallsnapshotReply) |
- 流程
- 获取锁
- 判断args.Term是否小于rf.term
- 小于说明leader失去时效性,解锁直接返回即可
- 根据args更新自身term和state等相关信息,解锁
- 单独开一个协程向rf.applyCh发送installSnapshot的相关参数
1 | go func() { |
1 | func (rf *Raft) CondInstallSnapshot(lastIncludedTerm int, lastIncludedIndex int, snapshot []byte) bool |
- 流程
- 获取锁
- 判断lastIncludedIndex和rf.commitIndex
- 小于,说明已经有更新的snapshot了,直接返回false
- 判断lastIncludedIndex与rf.LogTail().Index的关系
- 大于等于,只保留第一个空的占位log entry
- 小于保留lastIncludedIndex之后的log entry
- 更新第一个占位log entry( rf.log[0] )的Index=lastIncludedIndex,Term=lastIncludedTerm,Command=nil
- 更新rf.commitIndex = lastIncludedIndex,rf.lastApplied = lastIncludedIndex
- SaveStateAndSnapshot
- return true
测试
编写脚本测试500次,全部通过。

整个lab 2单次test用时约为5min40s。

注意
- Snapshot()中直接对rf.log = rf.log[index:]进行日志丢弃是不合理的 ,go的切片机制导致截取slice时,不会创建新的数组,只是简单的改变了引用的范围,前面的内容不会被gc进行回收,可以通过append方法创建新的数组,确保之前的底层数组会被回收
参考内容 && 致谢
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Hongwen Xin's Blog!