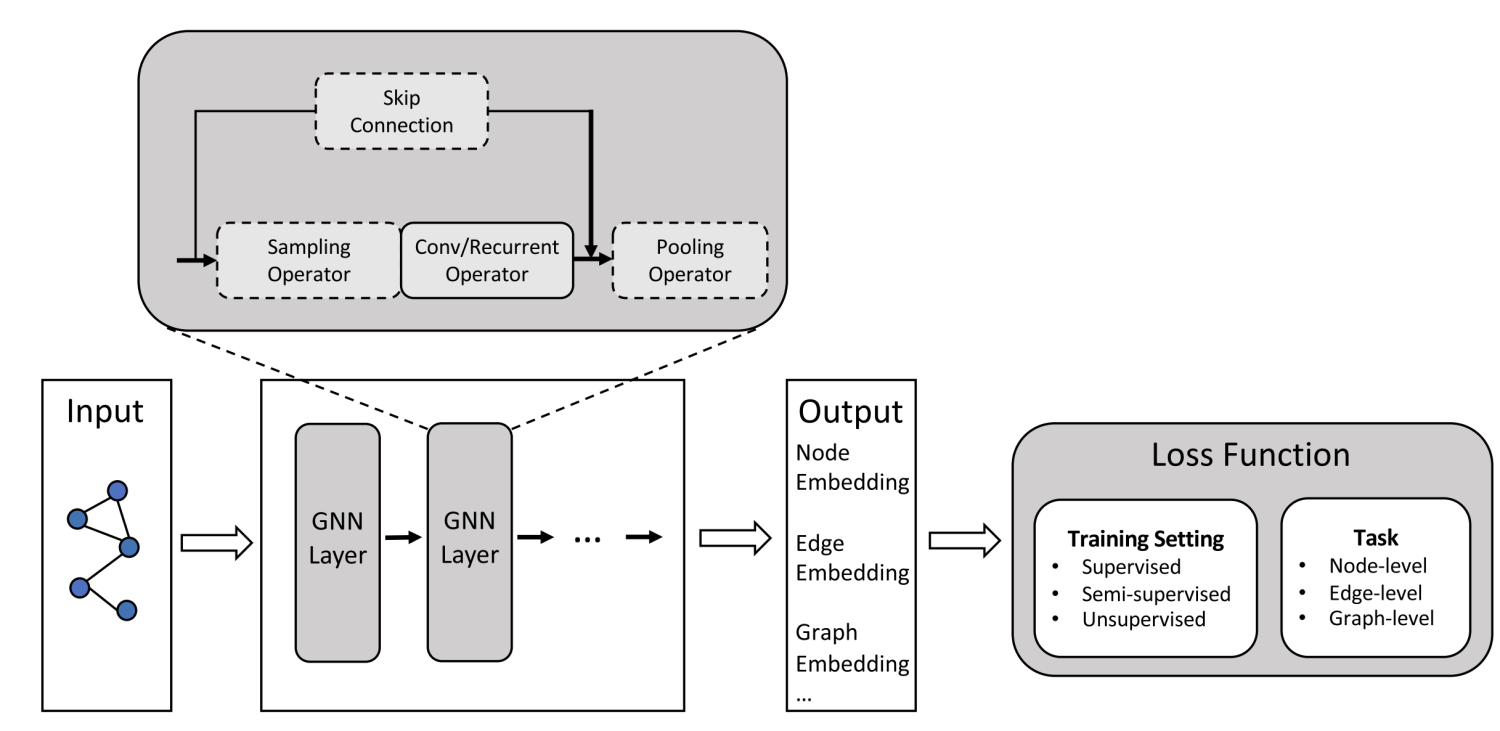
GPU相关
本文主要是自己对于GPU相关知识的总结,以Nvidia系列GPU为主,具体的架构和编程相关可能会在之后写cuda内容的时候介绍。
GPU发展历程
早期阶段(1980年代): 最初,GPU(Graphic Processing Unit)主要用于处理简单的2D图形,用于显示计算机屏幕上的图像。这些早期的GPU是图形加速卡的一部分,用于图形用户界面(GUI)操作和基本的图形渲染。
3D加速的兴起(1990年代): 随着电脑游戏和3D图形应用的兴起,GPU逐渐开始支持3D图形加速。3D加速卡开始崭露头角,提供更快的三维图形处理和渲染。NVIDIA和ATI(后来被AMD收购)等公司在这个时期推出了一系列创新的产品。
通用计算(2000年代): GPU不再仅限于图形处理,而是开始进入通用计算领域。CUDA(NVIDIA的并行计算架构)和OpenCL等技术使开发者能够利用GPU的并行处理能力执行更广泛的计算任务,如科学计算、数据分析和人工智能。
深度学习和人工智能(2010年代至今): GPU在深度学习和人工智能领域的发展迅速。由于深度学习模型对大量数据和大规模并行处理的需求,GPU的并行计算能力成为训练神经网络的理想选择。NVIDIA的CUDA架构和基于Pytorch等深度学习框架的优化使GPU成为训练和推理神经网络的首选硬件之一。
异构计算和AI加速(2020年代): GPU不仅限于传统的图形和通用计算任务,还在AI加速领域继续发展。除了NVIDIA之外,公司如AMD和英特尔也在努力开发支持AI加速的GPU架构。同时,出现了专门用于加速机器学习和深度学习任务的专用芯片,如NVIDIA的Tensor Cores和Google的TPUs(张量处理单元)等。
CPU vs GPU
现代深度学习为什么选择GPU而不是CPU?

图像来自于CUDA C++编程指南
CPU
- CPU的内核数量较少,常见的有4核和8核
- 由于CPU一般需要处理低延时任务,因此需要大量的L1,L2,L3 cache来减少访问指令和数据时产生的延迟,如上图左边所示,大部分晶体管用于构建控制电路和存储单元,少部分晶体管用来完成实际的运算工作
- CPU的每个核心都可以处理不同的指令序列,每个核心都有自己的控制器和缓存单元,擅长逻辑控制,适合处理串行和复杂的任务
GPU
- GPU拥有大量的小型核心,通常为数百至数千核心
- GPU的关注点不在于低延时和控制,对cache的需求相对较小,可以用大部分的晶体管来构建计算核心,如上图右边所示,这些核心可以执行大量的相似操作,在处理大规模数据和并行任务时非常高效,缺点是单核自由度远远低于CPU
在上图中,GPU的每一行(红框)有多个核,但是只有一个控制单元和L1 cache,表示这多个核在同一时刻只能执行相同的指令,这种模式被称为SIMT(Single Instruction Multiple Threads)。
在深度学习中涉及大量的矩阵运算,这种计算方式属于计算密集型,且操作重复,易于数据并行,非常适合于交给GPU进行任务的执行。
- 计算密集:数值计算的比例远大于内存操作,内存访问的延时可以被计算掩盖,因此对cache的需求相对CPU没有那么大
- 数据并行:大量的数据可以拆分为执行相同指令的小任务,对复杂流程控制的需求较低

来自于李沐老师的视频
- CPU边上绿色的是主存
- GPU的内存就是显存
- GPU核数量远远大于CPU,每秒计算数可以简单理解为核的数目*主频
- GPU的控制流远远弱于CPU,因为CPU要处理很多复杂任务,很多的if-else
总结
- CPU:可以处理通用计算
- GPU:使用更多的小核和更大的内存带宽,适合能大规模并行的计算任务
通信
GPU并不能单独工作,需要与CPU协同处理任务,流程大概如下

图像来自于谭升的博客
- CPU准备数据并分配GPU内存
- 拷贝数据到GPU中(可能多个GPU协同工作)
- GPU开始执行数据任务,期间CPU可以做自己的事情
- GPU计算完成将结果拷贝回CPU
- 销毁内存
其中数据的传输可以被看作外部通信,主要有三种方式。
PCIe

图像来自于李沐老师的视频(https://www.bilibili.com/video/BV1TU4y1j7Wd?p=1&vd_source=c3ee641e50e4973352c9085f2fd7974e)
- PCIe(Peripheral Component Interconnect Express)是一种计算机总线标准,用于连接各种内部硬件设备,如图形卡、网卡、存储设备和其他扩展卡到主板上的插槽。它提供了高带宽和高速度的数据传输通道,是现代计算机系统中最常见的总线标准之一
- PCIe的版本通常用"x"表示,例如PCIe 3.0、PCIe 4.0、PCIe 5.0等。每个版本的PCIe都有不同的数据传输速率和带宽。新版本通常会提供更高的速度和带宽,以适应不断增长的数据传输需求
- PCIe的速度通常以“xN”表示,N代表总线的通道数。PCIe 3.0 x16具有每秒达到约15.75 GB/s的速度,而PCIe 4.0 x16则将速度提高到每秒达到约31.51 GB/s,PCIe 5.0则进一步增加了速度,提供了更高的带宽
NVLink

在nvlink之前,为了获得更多强力的计算节点,可以用将多个GPU通过PCIe与CPU直接相连,他们之间的pcie 3.0*16有接近32GB/s的双向带宽,但是当训练数据不断增长时,这个互联方案会成为系统的bottleneck。
为了解决这个问题,NVidia开发了全新的互联架构NVLink,主要用于多GPU系统之间的互联,实现显存和性能扩展。

同时NVidia还发明了NVSwitch技术来连接多个NVLink,在单节点内和节点间实现以 NVLink 能够达到的最高速度进行多对多 GPU 通信。

GPUDirect RDMA
上面两种通信方式一般用于单机多卡GPU通讯,而GPUDirect** **RDMA(Remote Direct Memory Access)一般用于多机多卡GPU通信,RDMA是一种绕过远程主机而直接访问其内存中数据的技术,通过这种方式允许GPU直接访问RDMA网络设备中的数据,无需通过主机内存或CPU的中介。

N厂GPU架构
架构统计截止到文章发布2023年11月2日。
术语解释
- SM:Stream Multiprocessor,流多处理器,SM是一个并行处理单元,用于执行并行计算任务,为了处理大规模并行工作负载而设计的,涉及诸如图形处理、深度学习训练、科学计算和其他需要大量并行计算的任务。每个SM包含多个CUDA核心(CUDA Cores),这些CUDA核心能够执行并行指令,执行数学计算、逻辑操作和其他运算。同时,SM还包括一些高速缓存和寄存器文件,这些缓存和寄存器用于存储数据和指令,以便于处理任务
- FLOPS:每秒浮点运算次数(Floating Point Operations Per Second),是衡量计算机或处理器性能的指标
- CUDA Core:CUDA Core是NVIDIA GPU上的计算核心单元,用于执行通用的并行计算任务,是最常看到的核心类型。NVIDIA 通常用最小的运算单元表示自己的运算能力,CUDA Core 指的是一个执行基础运算的处理元件。CUDA Core 数量,通常对应的是 FP32 计算单元的数量
- Tensor Core:Tensor Core 是 NVIDIA Volta 架构及其后续架构(如Ampere架构)中引入的一种特殊计算单元。它们专门用于深度学习任务中的张量计算,如矩阵乘法和卷积运算。Tensor Core 核心特别大,通常与深度学习框架(如 TensorFlow 和 PyTorch)相结合使用,它可以把整个矩阵都载入寄存器中批量运算,实现十几倍的效率提升
Fermi - 2010


- 第一个为高性能计算应用提供所需功能的架构
- 支持符合IEEE 754-2008标准的双精度浮点
- ECC支持
- 多级别缓存
- 第三代SM,16个SM
- 每个SM有32个CUDA Core
- Dual Warp Scheduler 同时调度和分派来自两个独立 warp 的指令
- NVIDIA GigaThread TM 引擎
- 并发内核执行
- 乱序线程块执行
- 代表产品
- NVIDIA GeForce GTX 480
- NVIDIA GeForce GTX 580
Kepler - 2012


- 将SM升级为SMX,15个SMX
- 每个SMX有192个单精度的CUDA Core,64个DP双精度运算单元
- 为高性能科学计算而设计,减少SMX单元数,增加每组SMX单元中CUDA内核数
- 相比Fermi架构效率更高,性能更好
- 双精度浮点运算能力高并更加强调功耗比
- 代表产品
- NVIDIA GeForce GTX 680
- NVIDIA Tesla K40
- NVIDIA Quadro K5000
Maxwell - 2014


- SM升级为SMM,16个SMM
- 每个SMM中4个处理块,每个处理块有32个CUDA Core
- CUDA Core总数从Kepler架构的192个减少到128个,但是每个SMM单元拥有更多的逻辑控制电路,便于精确控制
- 支持统一虚拟内存技术,允许CPU直接访问显存和GPU访问主存
- 代表产品
- NVIDIA GeForce GTX 970
- NVIDIA GeForce GTX 980
- NVIDIA Tesla M40
- NVIDIA Quadro M6000
Pascal - 2016


- 改进设计,第一个考虑Deep Learning的架构
- 将处理器和数据集成在同一个程序包内,以实现更高的计算效率
- 60个SM
- 单个SM中设置2个处理块,每个处理块有32个FP32 CUDA Core,即单个SM只有64个CUDA Core,少于Maxwell的128个和Kepler的192个
- 单个SM增加了32个FP64 CUDA Core,即DP Unit
- NVLink

- 提供了NVLink用以单机内多GPU内的点到点通信,带宽达到了160GB/s, 大约5倍于PCIe 3.0 x16
- 代表产品
- NVIDIA Tesla P100
- NVIDIA GeForce GTX 1080
- NVIDIA GeForce GTX 1070
- NVIDIA Quadro P6000
Volta - 2017


- 对SM重新设计,比前代Pascal设计能效高50%,以Deep Learning为核心
- 新增Tensor Core
- 84个SM
- 单个SM设置4个处理块,每个处理块设置8个FP64 CUDA Core,16个INT32 CUDA Core,16个FP32 CUDA Core,2个Tensor Core,共160+8个Core
- 独立线程调度,不同于以前的SIMT架构,即一个线程束(Warp)中的32个线程共享一个程序计数器和栈,而Volta架构中每个线程都有自己的程序计数器和堆栈,使得线程之间的细粒度控制成为可能
- 升级NVLink
- 代表产品
- NVIDIA Tesla V100
- NVIDIA Titan V
- NVIDIA Quadro GV100
Turing - 2018


- 这一代中去掉了对FP64的支持
- 加入专门用于光线追踪的RT(Ray-Tracing),使得实时光线追踪成为可能
- 增加了深度学习超采样(Deep Learning Super Sampling, DLSS),它是由NVIDIA开发的一种基于深度学习的图形增强技术,通过利用人工智能和机器学习技术提高实时图形渲染的性能和画质,特别是在游戏中。
- 72个SM
- 每个SM中有4个处理块,每个处理块有16个INT32 CUDA Core,16个FP32 CUDA Core,2个Tensor Core,共128+8个Core
- Tensor Core中增加了对INT8/INT4/Binary的支持,深度学习的量化部署渐渐成熟
- 代表产品
- NVIDIA GeForce RTX 2080 Ti
- NVIDIA GeForce RTX 2070 Super
- NVIDIA Quadro RTX 6000
- NVIDIA Titan RTX
- NVIDIA Tesla T4
Ampere - 2020


- 升级了Tensor Core
- Ampere A100中Tensor Core的性能比Volta架构中Tensor Core的性能提高了2.5倍,比传统CUDA Core执行单精度浮点乘加的性能提高了20倍
- 84个SM
- 又把FP64加回来了
- 单个SM有4个处理块,每个处理块有8个FP64 CUDA Core,16个FP32 CUDA Core,16个INT32 CUDA Core,1个Tensor Core
- 代表产品
- NVIDIA A100 Tensor Core GPU
- NVIDIA A800 Tensor Core GPU
- NVIDIA GeForce RTX 3080
- NVIDIA GeForce RTX 3090
- NVIDIA Quadro RTX 8000
Hopper - 2022


- 新增Transformer Engine,Transformer模型的训练速度是上一代的6倍
- 动态编程指令(DPX)
- NVLink第四代
- 支持PCIe 5.0并采用了HBM3,有5TB/s的对外带宽和3TB/s的内部存储带宽
- 144个SM
- 每个SM有4个处理块,每个处理块有16个INT32 CUDA Core,32个FP32 CUDA Core,16个FP64 CUDA Core,1个Tensor Core(第四代)
- 代表产品
- NVIDIA H100 SXM5
- NVIDIA H100 PCIe
常见N厂GPU&&价格
| 产品型号 | GPU | 架构 | SM个数 | CUDA Core个数 | Tensor Core个数 | FP32单元峰值(GFLOPS) | Tensor单元峰值(TFLOPS, FP16) | 存储器接口 | 存储器大小 | 内存带宽(GB/s) | 散热功耗TDP/瓦 | 晶体管数量/10亿 | 芯片大小/ | 工艺/nm | 二级市场价格/¥(截止到2023-11-2) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NVIDIA GeForce GTX 580 | GF110 | Fermi | 16 | 512 | NA | 1332 | NA | 384-bit GDDR5 | 6GB | 192.4 | 250 | 3.0 | 520 | 40 | NA |
| NVIDIA Tesla K40 | GK100 | Kepler | 15 | 2880 | NA | 5046 | NA | 384-bit GDDR5 | Up to 12GB | 288.4 | 235 | 7.1 | 551 | 28 | 4599 |
| NVIDIA Tesla M40 | GM200 | Maxwell | 24 | 3072 | NA | 6844 | NA | 384-bit GDDR5 | Up to 24GB | 288.4 | 250 | 8.0 | 601 | 28 | 998 |
| NVIDIA Tesla P100 | GP100 | Pascal | 56 | 3584 | NA | 10609 | NA | 4096-bit HBM2 | 16GB | 732.2 | 300 | 15.3 | 610 | 16 FinFET+ | 3899 |
| NVIDIA Tesla V100 | GV100 | Volta | 80 | 5120 | 640 | 15670 | 125 | 4096-bit HBM2 | 32GB | 897 | 300 | 21.1 | 815 | 12 FFN | 36999 |
| NVIDIA Tesla T4 | TU104 | Turing | 40 | 2560 | 320 | 8141 | 65 | 256-bit GDDR6 | 16GB | 320 | 70 | 13.6 | 545 | 12 | 6699 |
| NVIDIA A100 PCIe 80GB | GA100 | Ampere | 108 | 6912 | 432 | 19490 | 312 | 5120-bit HBM2e | 80GB | 1935 | 300 | 54.2 | 826 | 7 | 180000 |
| NVIDIA H100 PCIe 80GB | GH100 | Hopper | 132 | 16896 | 528 | 62080 | 969 | 5120-bit HBM3 | 80GB | 2039 | 350 | 80 | 814 | 4 | 240000 |
本表大部分数据来自于通用图形处理器设计-GPGPU编程模型与架构原理,价格部分来自于京东,顺带推荐GPU数据查询网站GPU Database。
V100 vs A100 vs H100

参考&&致谢
- 通用图形处理器设计-GPGPU编程模型与架构原理
- 英伟达GPU架构演进近十年,从费米到安培
- 丽台科技
- Evolution of the Graphics Processing Unit(GPU)
- 李沐老师的视频
- 谭升的博客
- ChatGPT
- NVIDIA技术
- nvidia nvlink互联与nvswitch介绍
- 聊透 GPU 通信技术——GPU Direct、NVLink、RDMA
- nvlink-bridges
- NVIDIA_CUDA_Programming_Guide
- GPU架构与计算入门指南
- NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf
- NVIDIA-Kepler-GK110-GK210-Architecture-Whitepaper.pdf
- NVIDIA_Maxwell_GM204_Architecture_Whitepaper.pdf
- pascal-architecture-whitepaper.pdf
- volta-gpu-architecture/Volta-Architecture-Whitepaper-v1.1-CN.compressed.pdf
- NVIDIA-ampere-GA102-GPU-Architecture-Whitepaper-V1.pdf
- gtc22-whitepaper-hopper
- GPU Database